0. 개요
C 언어를 이용해 가상의 쉘을 구현하는 프로젝트이다.
정확히는 bash를 모방해야 하는데 zsh나 다른 쉘과 동작에 차이가 있으니 주의해야한다.
문자열을 입력 받을 수 있는 화면을 띄우고, 화면으로 명령을 입력 받으면 실행 순서와 입출력 연결등을 고려해 명령을 구조화하고, 실행하여 화면에 출력하는 것이 목표이다.
상세한 요구사항은 다음 문서에 담겨있다.
-by 42seoul-translation
구현한 코드는 다음 GitHub 레포지토리에 가면 확인할 수 있다.
-with 42seoul-jeounpar
진행 기간
2022.07.06 ~ 2022.07.22
0.1. 역할 분담
프로젝트는 크게 2가지 작업으로 나눌 수 있다.
-
입력 받은 문자열을 실행 순서 등이 고려된 일련의 명령으로 구조화 하는 부분. (이하 parsing)
-
구조화된 명령을 집행하는 기능을 구현하는 부분. (이하 executing)
두 명이 병렬적으로 프로젝트를 진행하기 위해 parsing 의 결과로 executing에 넘겨질 반환값에 대한 스키마를 그리고,
각자의 파트를 10일간 구체화하여 다시 모여 그것을 이어붙이기로 했다.
파트의 결정은 사다리타기를 이용해 결정되었고, 그 결과 내가 parsing, jeounpar 씨는 executing을 맡게 되었다.
1. 진행 상황
2022.07.06
jeounpar과 처음 대면하여 프로젝트 요구사항을 읽고 그에 대한 밑그림을 그려보았다.
I/O Redirection 등에 대해 서로의 이해가 부족하여 이 부분에 대해 서로 공부하고 다음날 다시 만나기로 했다.
2022.07.07
각자의 이해를 바탕으로 필요한 기능들을 구체화하고, task들을 묶어 2개의 파트로 나누었다.
2개의 파트의 구현이 동시에 진행 될 수 있도록, 파트간 오갈 자료형에 대해 정의했다.
2개의 파트에 대해 서로의 합의하에 사다리타기를 하여 각자의 역할을 결정했다. (chanhale: parsing, jeounpar: executing)
Parsing 파트 상세
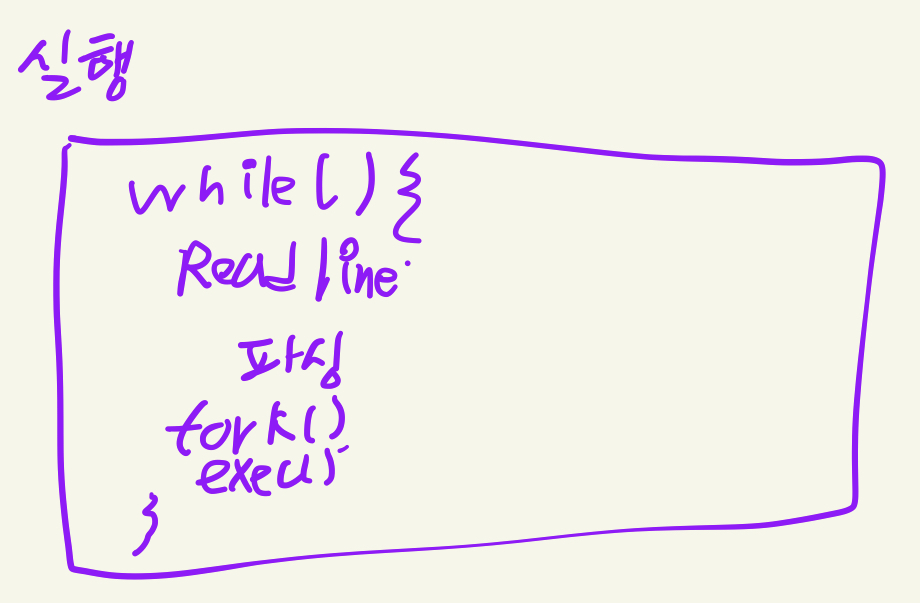
parsing 파트는 해당 결과를 입력값, 그리고 구조화된 명령을 출력값으로 한다.
t_cmd 라는 구조체를 노드로 하는 linked list로 명령을 구조화하기로 합의하였다. (이는 2022.07.08 에 수정된다.)
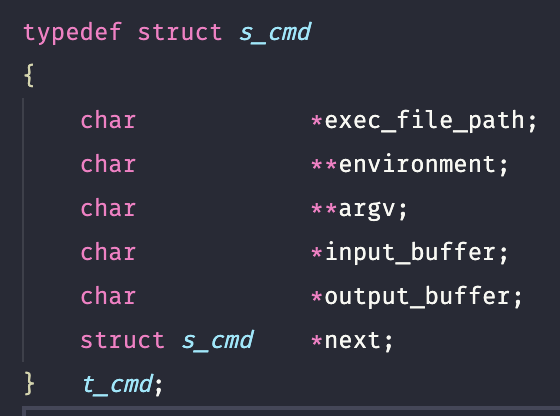
문자열을 구조화하는 방법은 마치 사칙연산의 연산 순서를 결정하듯이 명령의 실행순서를 결정할 구문트리 (Abstract syntax tree)를 디자인한다.
그것을 통과시킨 결과를 t_cmd 로 구성된 linked list로 만들어 구조화하고 반환한다.
2022.07.08
여기서부턴 jeounpar의 진행을 구체적으로 알지 못한다. (나의 진행도를 위주로 기술하겠다.)
t_cmd를 구체적으로 디자인하고, create 함수와 free함수를 만들었다.
수정 사항
자료형을 수정하였다.
수정된 구조체들(2022.07.08 ver)
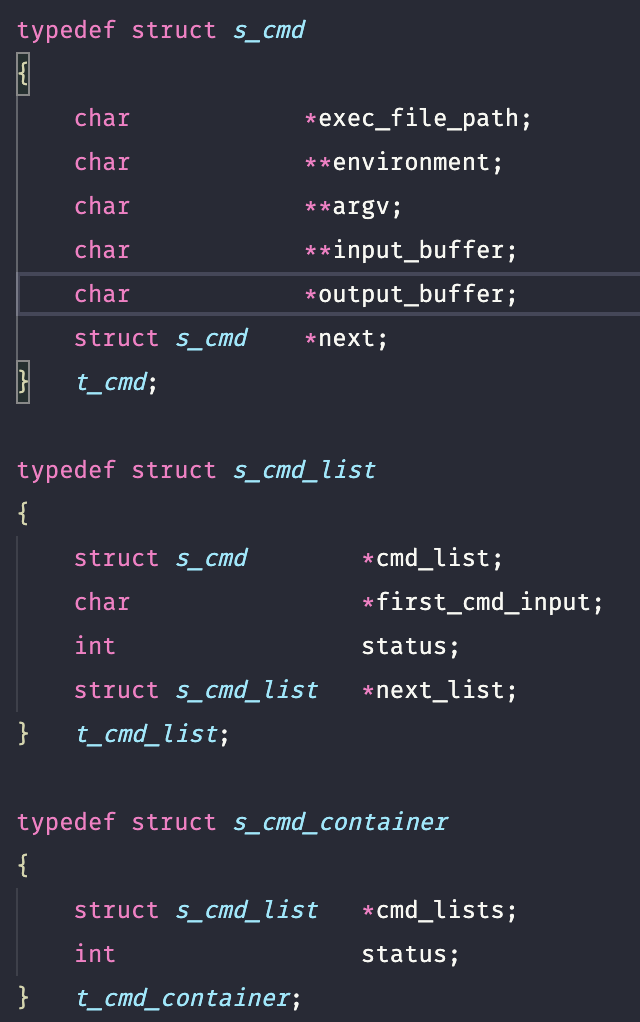
선행 노드의 output이 자신의 input으로 연결되어야 한다는 것을 고려하여 input_buffer 를 ‘char *‘가 아닌 ‘char **‘로 변경하였다.
그리고 가장 처음 나오는 노드의 input을 따로 보관하기 위햐 t_cmd_list라는 구조체을 추가하였다.
또한, ‘;’으로 구분된 여러 덩이의 명령이 입력될 경우 하나의 linked list로 묶을 수 없다는 것을 알게 되었고,
이를 해결하기 위해 명령들을 담는 t_cmd_container 라는 구조체를 새로이 정의하였고,
t_cmd_container 내에 t_cmd_list 를 linked list 형태로 여러개 보관할 수 있도록 하였다.
이에 따라 parsing 파트의 최종 결과물은 t_cmd_container *이 되었다.
2022.07.10
-
요약
개념 공부를 다시했다.
잘못 알고 있는 것 몇 가지를 제대로 알게됐고, 이해하지 못했던 부분들이 점점 이해됐다.가설을 세우고 bash로 검증을 해가며
parsing 파트의 흐름을 디자인 했다. —-
처음엔 무작정 파싱 과정을 알아내기 위해 구글링을 했으나 별 소득이 없었다.
일단 구글링으로 정보를 얻는데 한계를 느껴 일단, 내가 알고 있는 것을 토대로 가설을 세우고, bash에 입력해가며 세부적인 순서를 조정해갔다. 머리가 나빠서인지… 여기에 8시간정도를 소모했다.
그 8시간의 결과물은 아래 파싱 개념부분에 따로 적겠다.
2022.07.13
-
요약
토큰화를 어느정도 마무리 지었다.
토큰화만 가지고 3일 내내 지지고 볶았다.
하루 10 시간을 하나의 파트를 가지고 코딩하다보니 진지하게 토나올 것 같다.
토큰화 파트를 구현하면서 가장 힘들었던 것은 다음 2가지이다.
-
역설계식 진행
bash가 입력을 어떻게 토큰화 하는지 알 수가 없었다. 설계 전에 세웠던 가설들을 검증해가며
반례가 나오면 그것을 포함하는 가설을 세우고, 그런식으로 처음의 가설을 수십번 뜯어 고쳤다.
새로운 패턴을 적용한 부분들이 기존에 짰던 부분과 협응하지 않을 경우 기존 코드들을 손보고.
(그… 다 알죠? 이거 진짜 끝도 없이 작업 많아지는거… )
-
norminette
42Seoul 만의 코딩 컨밴션이다. 진짜 매 프로젝트에서 이게 정신을 많이 깎아먹는데 minishell
에서는 그게 심했다. 함수 하나에 최대 25줄, 1줄은 최대 85자 제한, static 및 전역변수 생성
불가… 42 교육생이라면 모두가 공감할 수 있는 스트레스원일 것이다. 멘탈 강화에 정말 특효약이긴
한데… 긍정적으로 생각하자. 좋은 생각 좋은 생각
2022.07.14
-
요약
토큰화를 완전히 마무리 짓고, syntax err 처리와 명령 구조화를 구현했다.
원래 계획은 토큰화와 명령 구조화 사이에 argv 토큰에 실행파일명, io 파일명 등으로 세부역할을 규정하는 단계가 있었다. 이때 syntax err 도 같이 잡게 되는데 세부역할 규정을 명령 구조화 파트에 넣고, syntax err 만 명령 구조화 전에 처리하는 식으로 변경했다.
execve 함수의 경우 첫번째 인자에 실행할 파일 명 뿐만 아니라 파일의 경로(PATH)까지 첨부되어 있어야한다. jeounpar 님과 화상 회의에서 t_cmd의 exec_file_path에 실행파일의 정확한 위치와 실행파일명을 넣어주기로 했는데 해당 디렉터리에 있는 것이 실행 가능한지 검증하는게 불가능했다. 따라서 parsing파트에서 PATH에 저장된 수많은 경로 중 유효한 경로를 특정짓는 것이 어렵다고 생각해 PATH 를 char **로 전달하는 식으로 변경하기로 했다. execve 를 실행할 때 실행파일 명과 PATH 를 하나씩 strjoin하여 실행해보는 식으로 변경되겠다.
2022.07.15
-
요약
jeounpar 님과 화상회의로 각자의 진행사항을 공유하고 일요일까지 각자의 파트를 완성하여 서초 클러스터에서 만나기로 했다.
명령 구조화의 에러들을 잡아 내고 PATH에 대해 새로이 합의된 것을 반영하여 구조체를 일부 손봤다.
PATH를 획득하는 함수를 jeounpar 님 께서 만들어주신다고 하셔서 해당 함수가 필요한 파트를 제외하곤 모두 마무리 되었다.
-
남은 작업
- 실행파일명에 절대경로 or 상대경로가 이미 추가되어 있는지 확인하고 cmd status 업데이트.
- PATH 값을 cmd_list 에 첨부시키고, PATH를 하나씩 꺼내서 (실행파일 명에 경로가 추가되지 않았을 경우)실행파일명과 join하여 넘겨주는 함수 구현.
오늘과 내일은 그동안 밀린 여름방학계획을 처리해야겠다.
2022.07.20
-
요약
7월 15일부로 나의 주요한 작업들은 마무리 되었다. jeounpar 님이 담당하는 파트의 분량이 생각보다 많아서 어려움이 있는 것 같았다. 누구도 의도치 않았고, 사다리로 결정되었지만 불공평한 업무 배분으로 동료가 고생중이라 지속적으로 뭐든 도와드리겠다고 말씀 드렸지만, 자잘한 기능 요청 외에 크게 도움을 구하시지 않는다. 죄송하면서도 대단하다는 생각이 든다.
쉘에서 포크된 자식 프로세스에서 execve를 실행하기 위해 입력된 argv[0]가 자체적으로 (절대or상대)경로를 포함하고 있는지 검사하고, 포함하지 않는다면 PATH를 하나씩 결합하여 실행 성공까지 execve 를 실행하고, 포함한다면 별다른 조치 없이 execve(argv[0], argv, NULL) 을 실행하는 일종의 교환수 역할의 코드를 구현했다.
쉘 설계도 조금 더 구체화 되었다. 미니쉘 시동시 외부 쉘의 환경변수를 가져와 미니쉘의 전역변수에 저장하고 내부적으로 생성된 환경변수(전역변수에 담긴)를 조작할 수 있고, 그 환경변수들을 가져올 수 있는 ft_getenv 와 export 명령의 빌트인 버젼을 jeounpar 님이 구현하셨다. 나는 그것을 기반으로 parsing 파트의 환경변수 해석부분을 변경했다.
pipeline 관련하여 t_cmd 와 t_cmd_list 의 내용과 구조상 변화가 있었다.
t_cmd 는 하나의 명령에 대한 정보를 담는다. shell 은 파이프라인으로 전행 명령의 표준출력 결과를 후행 명령의 표준 입력으로 리다이렉션 하는 기능을 제공하는데 당초 설계시엔 어떤식으로 이루어지는지 몰라 어떤 버퍼에 전행의 결과를 담고, 후행에 그 버펴의 주소를 주는 형식으로 설계를 했었다. (프로젝트 초반의 구조체의 내용에 그것이 반영되어있다.) 그러나 pipeline이 전행의 표준출력 file discreptor 를 dup 으로 조작하여 후행의 표준 입력으로 보낸다는 것을 알게 되고, 이 버펴에 관한 내용이 구조체에서 빠지고, 대신 전행과 후행을 자유롭게 이동할 수 있도록 doubly linked list의 형식으로 t_cmd 를 엮는 형태로 변경했다. 또한 t_cmd_list 에 linked list 의 tail 을 보관하도록 개선했다.
변경된 구조체(2022.07.19 ver)
typedef struct s_cmd
{
char *exec_file_name;
char **argv;
int fds[2];
int fd_in;
int fd_out;
int type;
struct s_cmd_redirection *redirection_list;
struct s_cmd *next;
struct s_cmd *prev;
} t_cmd;
typedef struct s_cmd_list
{
struct s_cmd *cmd_list;
struct s_cmd *cmd_list_tail;
int status;
} t_cmd_list;
2022.07.21
-
요약
등록되지 않은 환경변수를 청구시 기존에는 “” 를 넘겨주었지만 이렇게 해서는 후술할 몇 가지 상황에 대응이 불가능했다.
이를 처리하기 위해 t_parse_token 구조체를 수정하고, ft_getenv 함수의 NULL 반환시 처리를 변경했다.
<< 연산자 뒤에 오는 chunk 는 env 파싱되어선 안된다. 이와 관련되어 env를 파싱하기 전 원형을 보존하는 기능을 구현했다.
getenv() 함수에 등록되지 않은 환경변수를 청구하는 경우 NULL 이 반환된다. 기존 코드에선 빈 argv 토큰으로 인식하여 NULL 값을 보존하지 않았다.
이럴 경우 ls $NOT_EXIST 의 실행이 ls "" 와 동일해지는데 bash 는 ls $NOT_EXIST 의 경우를 ls 으로 처리하여 현제 디렉터리를 ls 한 결과를 출력한다. 그런데 내가 처음 구현할 때 굳이 getenv() 의 반환이 NULL 인경우 토큰을 삭제하지 않고 빈 argv_token 으로 처리한 이유는 bash에서 $NOT_EXIST \| cat 의 처리가 \| cat 이 아닌 "" \| cat 와 같았고,
cat \| $NOT_EXIST 의 경우도 cat \| "" 과 같았기 때문이다. 여기에 더해 bash는 cat < $NOT_EXIST 를 처리할 때 at \< 로 인식하여 syntax_error 를 내보나지도 않고, at \< "" 으로 인식하여 "" 파일이 없다고 No such file or directory 를 내보내지도 않고, $NOT_EXIST: ambiguous redirect 를 출력하는 제 3의 동작을 한다. 즉 $NOT_EXIST 의 처리가 내부적으로 다양하게 해석된다는 것이다. 이를 처리하는 로직은 하단 파싱 이론 파트에 기록하겠다.
<< 연산자로 heredoc을 실행할 경우 cat \<\< $AA 는 $AA의 내용을 해석하지 않고, $AA 를 입력할 때까지 heredoc으로 입력을 받는다. env 가 파싱되기 전 raw String을 보존해야 하는데 이에 대한 처리도 필요했다. 이 역시 파싱 상세에 정리하겠다.
변경된 token 구조체(2022.07.21 ver)
typedef struct s_parse_token
{
int token_type;
int is_null;
char *original_str;
char *string;
struct s_parse_token *next;
} t_parse_token;
2022.07.20
*요약
Makefile을 작성하고, 디버깅에 사용하는 함수들을 프로젝트 디렉터리 바깥으로 옮겼다.
동료평가 3회를 모두 통과하여 과제를 마치었다.
몇 가지 사소한 에러들이 발견되어 수정하였고, 제출해도 되겠다는 서로의 동의하에 제출하고 평가를 잡았다.
첫번째 평가에서 고비가 있었다. 평가도중 single quotation 을 체크하는 도중 echo '$HOME' 명령에 $HOME이 출력되어야 정상이지만, 어째서인지
환경변수를 해석한 결과가 출력되었다. 환경변수 해석은 내가 맡은 파싱파트에서만 진행되었고, single quotation 의 파싱 또한 파싱파트에서 해석이 이루어진다.
내 잘못이었다는 생각에 죄책감과 ‘어째서?’ 라는 두가지 생각이 머릿속을 채웠다. 동료와 평가자에게 실수가 있었다고 죄송하다고 사과를 드리고 어디서 이런 결함이 발생했는가를 고민했다. 분명 초기 설계단계에서 확인했었는데! 사소한 오류 컨트롤 패턴 수준에서부터 parsing 이론까지 내가 직접 설계했고 두손으로 직접 코딩해서 속속들이 알고있는데… 논리적으로 분명 불가능한 동작인데… 그런데 그게 발생했다.
5점 감점되어 95점으로 평가가 끝나고 코드를 몇번이고 확인을 했으나 결함이 없었다. single quote 파싱 문제가 아닌 다른 파트의 결함이었다. 사람 마음이 간사하다는게 새삼 느껴졌다. ‘와.. 다행이다! 내 잘못이 아니었구나’ 라는 생각이 머릿속에 들어차며, 죄책감은 안도로 변했다.
사실 팀 프로젝트의 특성상 개인의 실수를 팀이 책임져야하고, 프로젝트가 완성되는 시점에 모두가 만약 내가 맡은 파트에서 결함이 발생하면 어쩌지? 라는 불안감이 있다. 그래도 서로의 작업을 믿고, 그리고 한편으로는 그 만에 하나의 상황이 발생하지 않도록 디버깅을 한다. 그리고, 이정도면 충분하다는 결론에 같이 도달하여 프로젝트 제출 버튼을 상호 동의 하에 누른다.
충분하다는 결론에 서로가 합의한 순간에 개인의 실수는 사라지고, 품질 검증 태만이라는 팀 전체의 잘못만 남아야 한다.
이 부분에 대해 프로젝트 제출을 누르기 전에 말을 꺼내지 않은게 아쉬웠다.
우리가 예측할 수 있는 테스트케이스들에 한계가 있고, 내 코드가 그 모든 테스트케이스를 통과할 수 있을까? 라는 의구심이 동료에게 ‘이제부턴 각자의 책임은 없어진다’는 말을 꺼내기 힘들게 한게 아닐까?
이후 평가에서 우리보다 먼저 minishell 과제를 하신 카뎃을 만났다. parsing 파트가 훌륭하다고 칭찬을 받았다.
다른 사람들이 일반적으로 사용하는 방식으로 parsing을 할 경우 대응하기 어려운 상황이 있는데 그런 부분에 대해 완벽하게 parsing을 했다고 칭찬해주었다.
일부러 다른 결과물 참고하지 않으며 직접 디자인한 parsing 패턴인데 진짜 기특한 내 새끼… 칭찬 들으니까 기분 날아갈 것 같았다.
첫 평가에서 발견된 오류는 다행이 평가 기준에는 없는 결함이었기에 두번째 세번째 평가에서 굳이 드러내지 않았으며, 그렇게 2, 3번의 평가는 101점, 100점을 받고 total 98점으로 프로젝트를 통과했다.
프로젝트 진행 기록은 여기서 마치겠다.
2. 파싱 이론
2.0. 개요
상기 진행 상황에서 잠깐 언급 했듯이 역설계식으로 만든 이론이다.
현상을 보고, 본질을 추정한 것이니 반례 하나에도 거짓이 되며 그 것을 바로잡는데는 단순히 파일 몇 개 수정에서 그치지 않고,
전체 구조를 바꿔야 할 오류일 수 있다.
파싱 파트의 입력 은 비어있지 않은 문자열이다.
파싱 파트의 출력 즉 최종 결과물은 순차적으로 정렬된 명령이다. (또는 syntex_error)
input: string
output: sequenced commands (or syntex_error)
2.1. 파싱 전체 순서
-
토큰화
string 들을 모두 토큰화 시킨다. (상세는 아래 세부 설명과 그림 참조.)
-
syntax_error 처리
pipeline_token의 앞, 뒤에 argv_token 가 없을 경우, I/O_red_token의 뒤에 argv_token 가 없을 경우 에 대해 syntax_error 처리
-
t_cmd_list 생성
argv_token의미부여, t_cmd 구조화가 여기서 이루어진다.
argv_token 들이 실행파일명인지, I/O_redirection 파일명인지 판단하고, pipeline_token 을 기준으로 토큰 더미를 나누어 t_cmd 들 만들고, t_cmd_list 에 그것들을 담는다.
이렇게 3단계로 나눌 수 있다.
2.2. 토큰화 상세
토큰 구조체
typedef struct s_parse_token
{
int token_type;
int is_null;
char *original_str;
char *string;
struct s_parse_token *next;
} t_parse_token;
토큰 관련 상수
# define TYPE_SYNTAX_ERR 999
# define TYPE_AMBIGUOUS_ERR 9999
# define TYPE_TOKEN_CHUNK 11
# define TYPE_TOKEN_ARGV 22
# define TYPE_TOKEN_SPACE 33
# define TYPE_TOKEN_PIPELINE 44
# define TYPE_TOKEN_EXEC 55
# define TYPE_TOKEN_IO_R 101
# define TYPE_TOKEN_IO_RR 102
# define TYPE_TOKEN_IO_L 103
# define TYPE_TOKEN_IO_LL 104
최초의 input은 chunk 라는 상태로 정의하겠다.
chunk 는 하나 이상의 chunk 또는 토큰으로 분리될 수 있는 가능성을 가진다.
-
토큰의 종류
argv_token, space_token, pipeline_token, I/O_red_token
argv_token
가장 기본적인 토큰이다.
ex) ls -la >aspace_token
의미 그대로 공백을 나타내는 토큰이다.pipeline_token
의미 그대로 파이프라인을 의미힌다.
ex) ls -la | catI/O_red_token
>, >>, 2>, &>, <, << 6종류가 있으나,
이번 프로젝트에선 >, >>, <, << 만을 고려한다.
ex) ls -la > a-
진행 순서
- input 된 string을 chunk 로 변경.
- "” 와 '’ 를 해석.
- $으로 시작하는 환경변수 해석.
- chunk로부터 공백을 찾아 space_token 으로 분리.
- 파이프라인( | ) 을 기준으로 pipeline_token 토큰으로 분리.
- I/O_redirection 연산자를 I/O_red_token 토큰으로 분리.
- 빈 chunk 소각, 모든 chunk 를 argv_token 으로 치환.
- 연속한 argv_token 병합.
- space_token 소각
-
과정 상세
-
input 된 string을 chunk 로 변경.
chunk 에서 “ 또는 ‘를 찾아 그것의 쌍이 나올때까지의 내용을 argv_token 으로 만들어 chunk 로부터 분리시키며 추출하는 것이다. "” 의 경우 내용의 $ 으로 시작하는 환경변수를 해석해야 한다.'’ 는 환경변수를 해석하지 않는다.
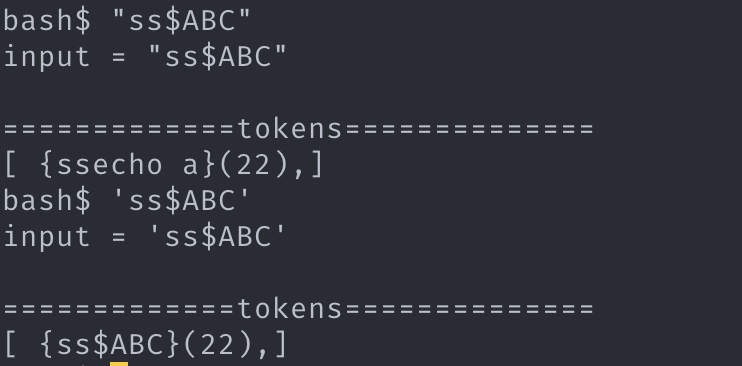
1. 구현 결과: chunk => chunk, argv_token, chunk
-
$으로 시작하는 환경변수 해석.
chunk 에서 환경변수를 해석한다. 여기가 조금 까다롭다. 해석된 환경변수는 argv_token 으로 인식되지만, 일반적인 argv_token의 경우 내부의 공백을 space_token으로 치환하지 않지만, 환경변수에서 생성된 argv_token 은 내부 공백에 대해 space_token 치환이 이루어진다.
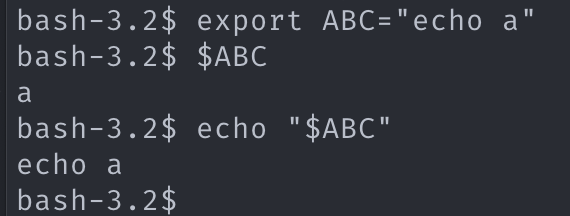
2. 근거 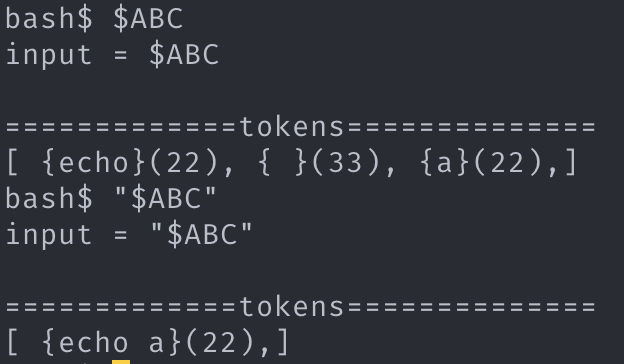
2. 구현 (2022.07.21 추가)
하기 추가분은 토큰의 성질에는 영향을 주지 않고, token에 세부 정보가 추가되어야 하는 것의 당위성을 주장하기 위함이다.
환경변수를 해석하기 전, $를 포함한 해석전 환경변수를 token 에 저장해야한다. heredoc 의 직후에 오는 경우 해석된 값이 아닌 그 원형의 입력 전까지 heredoc 입력을 받아야 하기 때문이다. 이에 더해 argv 토큰의 병합과정에선 이 환경변수의 original 문자열 또한 병합하여 보존해야 한다.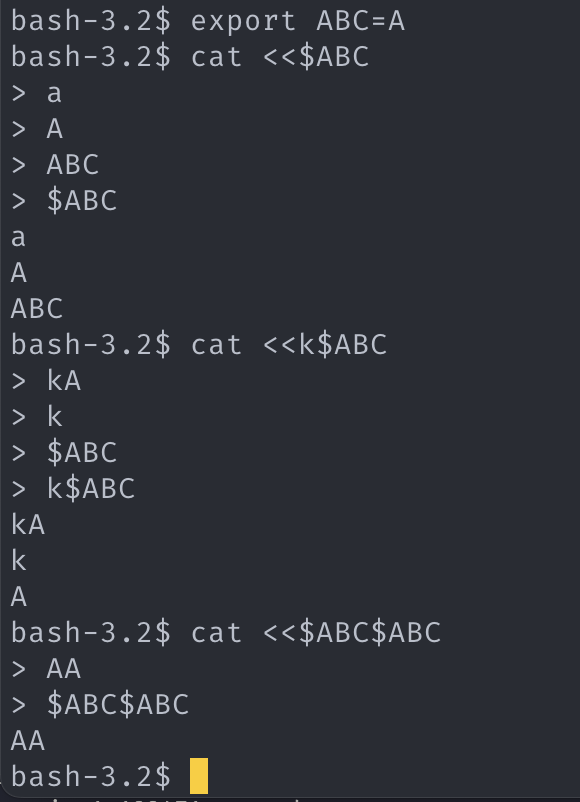
원형보존 근거 등록되지 않은 환경변수에 대한 해석도 다양하게 처리해야 한다. 이를 위해서는 상기의 토큰 원형 보존이 필요하다.
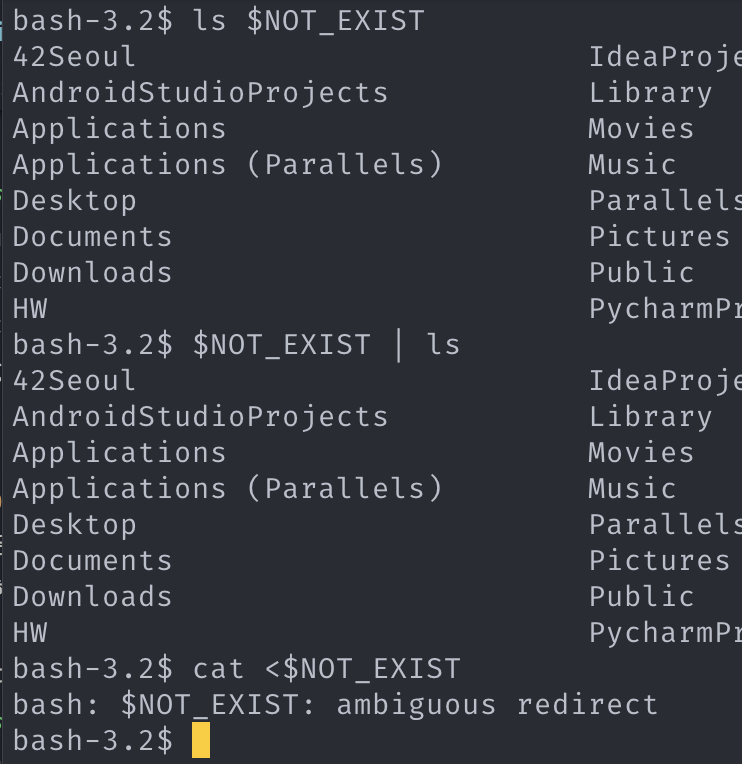
다양한 내부 해석 근거 -
환경변수 처리 분기 3가지
ls $NOT_EXIST=> 없는 토큰으로 처리$NOT_EXIST | ls=> “” 으로 처리cat < $NOT_EXIST=> syntax error 와 같이 tokenize 마지막 단계에서 구문 에러 처리하기
결과: chunk => chunk, argv_token, space_token, argv_token, chunk
-
-
chunk로부터 공백을 찾아 space_token로 분리.
chunk 에서 공백을 기준으로 2개의 chunk 와 하나의 space_token 으로 분리하는 것이다.

3. 구현 결과: chunk => chunk, space_token, chunk
-
파이프라인( | ) 을 기준으로 pipeline_token 토큰으로 분리
chunk 에서 “|“을 기준으로 2개의 chunk , 1 개의 pipeline_token 으로 분리한다.

4. 구현 결과: chunk => chunk, pipeline_token, chunk
-
I/O_redirection 연산자를 I/O_red_token 토큰으로 분리
chunk 에서 을 I/O 연산자를 기준으로 2개의 chunk , 1 개의 I/O_red_token 으로 분리된다.

5. 구현 결과: chunk => chunk, I/O_red_token, chunk
-
빈 chunk 소각, 모든 chunk 를 argv_token 으로 치환.
비어있는 chunk 들이 3, 4, 5 과정에서 생산되는데 이들을 소각한다. 비어있는 argv_token 은 소각시키면 안된다. (ls “” ./ 를 실행해보면 알 수 있다.)
그 다음 모든 chunk 를 argv_token 으로 변경한다.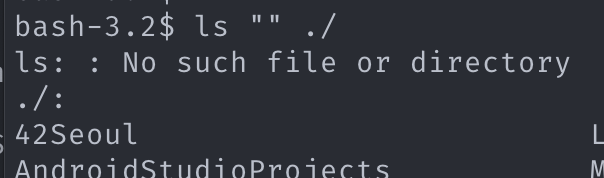
6. 근거 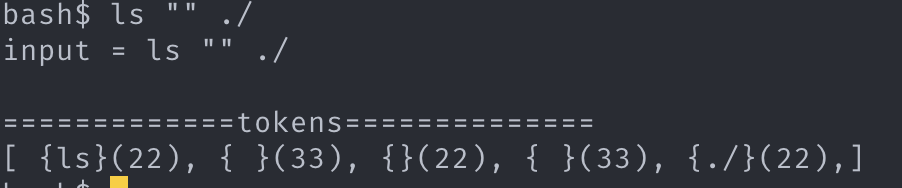
6. 구현 결과: chunk, chunk => argv_token
-
연속한 argv_token 병합.
연속한 argv_token 들을 하나의 argv_token 으로 병합한다. (아래 근거 사진 참고)
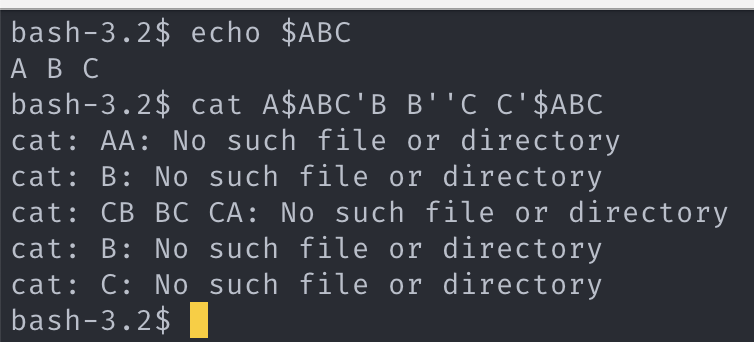
7. 병합 근거 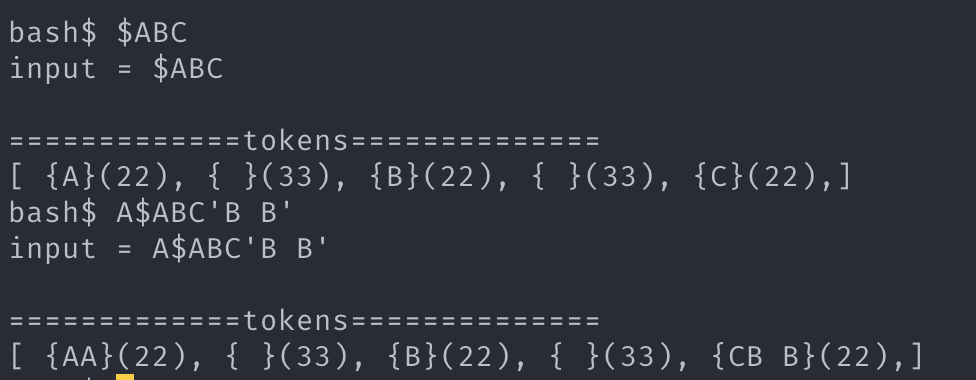
7. 구현 -
space_token 소각
space_token 의 역할은 7단계에서 이루어진 argv_token 병합의 구분자 역할을 하는 것으로 끝났다. 모두 제거하도록 하자.
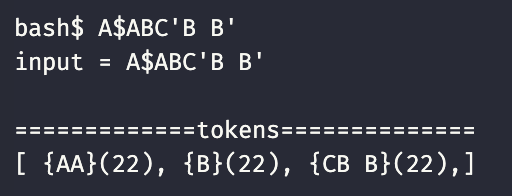
8. 구현 (7과 비교해 보기)
-
-
2.3. syntax_error 처리 상세
토큰화의 결과 argv_token, I/O_red_token, pipeline_token 으로 구성된 토큰 더미가 만들어진다.
이들을 대상으로 syntax_error 여부를 검사한다. 처리해야 할 syntax_error는 2가지이다. pipeline_token과 I/O_red_token 에 필요한 argv_token 이 적절하게 있는지 확인하는 것이다.
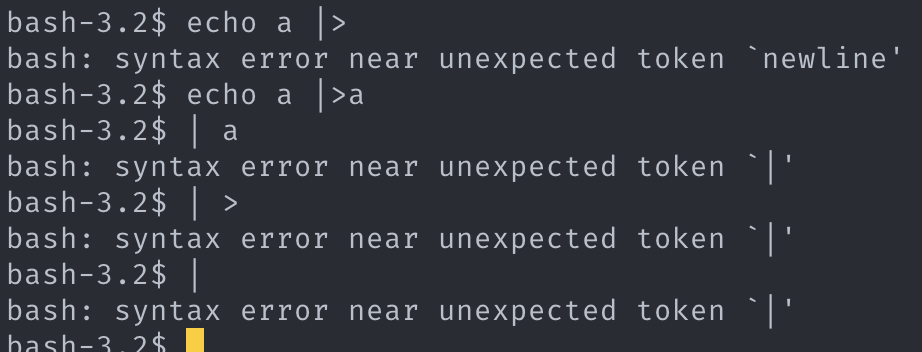
pipeline_token의 경우 앞과 뒤에 토큰이 있어야 하고,
argv_token의 경우 뒤에 argv_token 이 있어야 한다.
syntax_error 일 경우 execve가 실행되지 않고, error_message 가 쉘에 출력되어야한다. error_message 에는 어떤 토큰 때문에 syntax_error가 발생했는지 표기해야 하는데 이 blame 의 대상이 되는 tokken을 찾는 규칙은 다음과 같다.
-
규칙
- pipeline_token 의 앞에 있는 토큰이 NULL일 경우 pipeline_token 이 blame의 대상이 된다.
- pipeline_token의 뒤에 있는 토큰이 NULL일 경우 “newline” 이라는 가상의 토큰이 blame의 대상이 된다. (bash에서는 syntax_err 발생시키지 않고, 새로운 라인을 받으려고한다. 이에 대한 처리는 매우매우 복잡할 것으로 생각되어 syntax_err 으로 처리할 것이다.)
- pipeline_token의 뒤에 있는 토큰이 argv_token 가 아니더라도 syntax_err 를 발생시켜선 안된다.
- I/O_red_token 의 뒤의 토큰이 NULL 일 경우 “newline” 이라는 가상의 토큰이 blame의 대상이 된다. argv_token 가 아닌 다른 토큰 ( pipeline_token or I/O_red_token ) 이 온다면 그 토큰이 blame 의 대상이다.
-
규칙 근거
-
근거 1, 3
1. 3. 근거 (syntax_err_pipline) -
근거 4
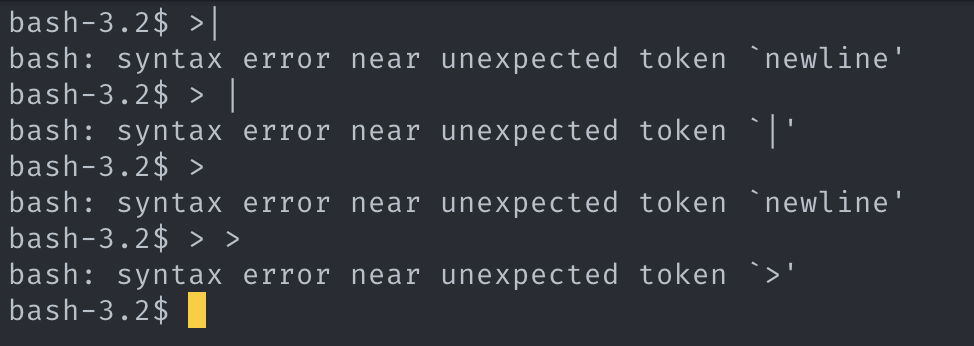
4. 근거 (syntax_err_I/O_red) -
근거 2
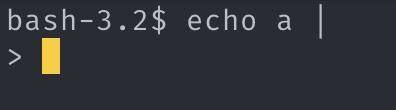
2. 증거 (왜 syntax err가 아닌지 모르겠는 것)
-
-
구현
-
구현 1. 3.
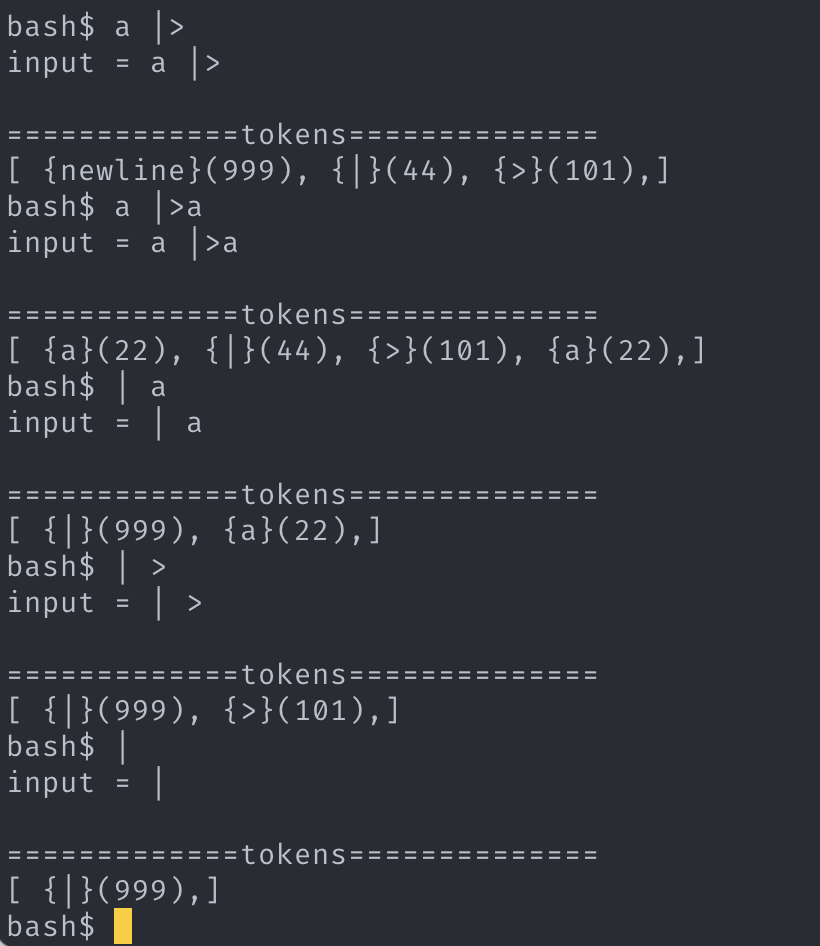
1. 3. 구현 (syntax_err_pipline) -
구현 4
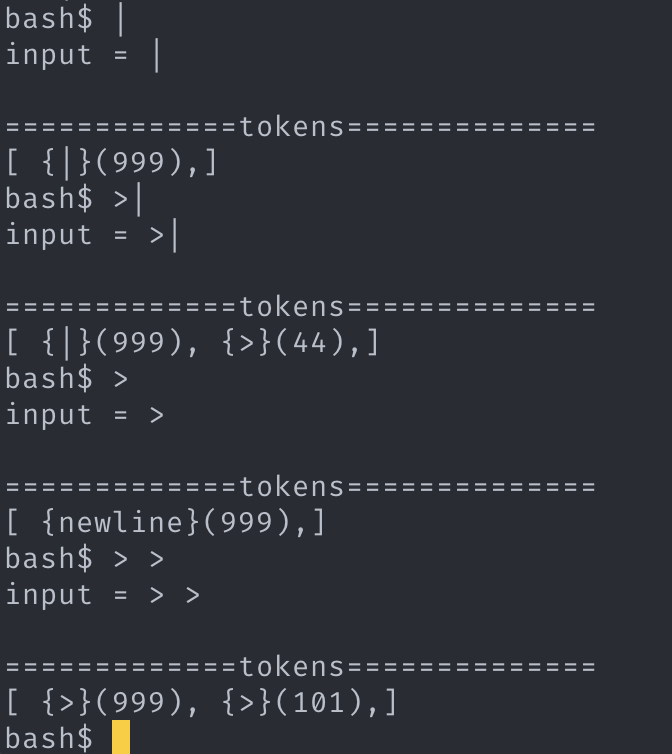
4. 구현 (syntax_err_I/O_red) -
타협안 2.
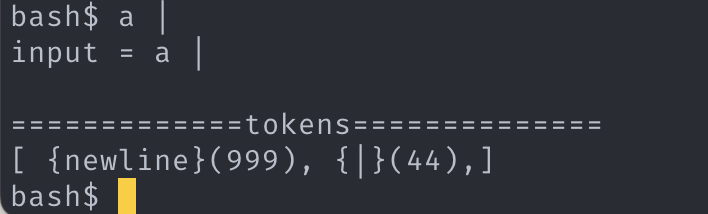
2. 타협안
토큰의 첫번째 상태값 (() 내에 있는 것) 이 999 일 경우 syntax_error를 뜻하고, 첫번째 상태값이 999일 경우 그 토큰의 메시지가 쉘에 출력될 blame 의 대상이다.
“4. 구현”을 자세히 보면 첫번째 blame 대상이 “4. 근거”와 다르다는 것을 알 수 있다. bash를 닮은 쉘을 만들어야 하지만, 납득되는 로직이 떠오르지 않아 그냥 두었다. (하드코딩을 하면 되긴하지만, 납득되는 코드만 짜기로 마음 먹었으니 소신껏 그대로 두겠다.)
-
2.4. t_cmd_list 생성 상세
-
개요
syntax_error 가 발생한 토큰더미는 이 과정을 거치지 않는다. (따로 처리된다.)
따라서 여기에 도착하는 토큰더 미들은 모두 syntax_error 발생 조건으로부터 자유롭다.이 토큰들이 실행 가능한 명령의 리스트(t_cmd_list)가 되기 위해서는 pipeline_token 을 경계로 분할되고, 그것들이 t_cmd 단위로 토큰들이 의미를 이루는 과정을 거쳐야한다.
t_cmd 를 이루기 위해 분할된 토큰 더미에서 argv_token은 다른 토큰과의 관계, 토큰의 위치(순서)를 고려해 의미가 부여된다.
-
사용한 구조체
t_cmd_list 구조체
typedef struct s_cmd_list { struct s_cmd *cmd_list; struct s_cmd *cmd_list_tail; int status; } t_cmd_list;t_cmd 구조체
typedef struct s_cmd { char *exec_file_name; char **argv; int fds[2]; int fd_in; int fd_out; int type; struct s_cmd_redirection *redirection_list; struct s_cmd *next; struct s_cmd *prev; } t_cmd;t_cmd_redirection 구조체
typedef struct s_cmd_redirection { char *file; int red_type; struct s_cmd_redirection *next; } t_cmd_redirection; -
진행 순서
-
t_cmd_list 를 만들고 해당 객체 내에 t_cmd 노드를 하나 생성하여 추가한다. ( t_cmd 는 링크드 리스트의 노드 형태로 t_cmd -> next로 다음 노드에 접근할 수 있다. )
-
토큰 더미에서 pipeline_token 이 관측되기 전까지 생성된 t_cmd 노드에 다음을 진행한다.
- I/O_red_token 의 뒤에 나오는 첫 번째 argv_token 은 I/O_red_token 에 종속되는 토큰이다. t_cmd 내의 t_cmd_redirection 리스트에 노드를 추가하고 I/O_red_token의 종류와 종속된 argv_token의 내용을 복사해 넣는다.
(혹여나 argv_token 이 없는 경우를 걱정할 필요는 없다. syntax_error 검증을 통과하지 못한다.) - 1의 실행 뒤에 argv_token 이 남았다면 하나씩 t_cmd->argv 에 추가한다.
(가장 처음 나온 argv_token은 t_cmd->exec_file_name 에도 등록시킨다.)
- I/O_red_token 의 뒤에 나오는 첫 번째 argv_token 은 I/O_red_token 에 종속되는 토큰이다. t_cmd 내의 t_cmd_redirection 리스트에 노드를 추가하고 I/O_red_token의 종류와 종속된 argv_token의 내용을 복사해 넣는다.
-
pipeline_token 이 관측되었다면 t_cmd_list 에 t_cmd 노드를 하나 생성하여 추가한다.
-
2.5. 후속 처리
t_cmd_list 가 생성되었으니 이를 실행파트에 건네주면 된다. (syntex_error 또한 그 정보를 담은 t_cmd_list 가 생성된다.
이를 넘겨받은 실행파트는 _t_cmd__->exec_file_name 의 내용이 상대경로, 절대경로 를 포함여부를 따지고, 포함하지 않는다면 PATH에 있는 내용들을 하나씩 join하며 execve 를 돌리면된다.
t_cmd->exec_file_name 이 NULL 인 경우가 있는데 (echo a | >a 와 같은 경우) 이때는 PATH와 결합할 실행파일명에 빈문자열을 넘겨주면 된다.
3. 느낀점
지금까지 42를 진행하면서 만난 프로젝트 중 가장 스케일이 큰 프로젝트였다.
시간적으로 가장 많은 자원이 투여되었고, 그만큼 각종 고민해볼 거리들을 많이 마주쳤다.
이 블로그를 만든 목적이 내 생각들을 보존하기 위함이니 오늘은 나의 다른 42 프로젝트 포스팅과 달리
생각들 중 가장 추상적이고, 가소성이 높으며 개인적인 ‘느낌’을 한번 정리해보고자 한다.
3.1. 팀 프로젝트로서 느낀점
사실 지난학기 장학금 어플 구현 프로젝트(acha-scholarship) 에서 팀장 역할을 하며 프로젝트를 완성했던 경험이 정말 도움이 많이 되었다.(이 때 느낀점은 따로 정리해야겠다.)
-
작업 정의 미숙
서로 연관된 task들을 병렬적으로 진행하기 위해 작업 정의 과정이 필요하다.
각자 역할에 대한 명확한 구분, 서로가 교환할 데이터에 대한 명확한 정의 등이 포함되는데,
다행이 jeounpar 님도 컴퓨터공학 전공자라 개발 프로젝트의 진행에 대해 경험이 있으셔서 작업 정의 가 수월했다.
- 프로젝트에 필요한 작업들의 리스트들을 만들고,
- 연관된 작업들을 2개의 덩어리로 묶고, (포함관계가 애매한 자투리 작업은 남겨놓는다.)
-
각자가 선호하는 덩어리가 무엇인지 의사교환을 한다.
- 여기서 둘의 선호가 중복될 경우 중복되는 작업에 자투리 작업들을 몰아주고, 사다리를 탄다. (우리는 둘다 parsing을 하고싶어했다.)
- 선호가 중복되지 않을 경우 각자가 원하는 작업과 2에서 남겨놓은 자투리 작업들을 공평하게 배분한다.
- 각자의 파트에 대해 고민한 뒤 서로의 파트에서 이루어질 데이터 흐름에 대해 자료형과 내용을 정의한다.
물론 전제가 까다롭다.
-
작업들에 대해 서로의 이해가 비슷한 수준이어야 한다.
백엔드, 프론트엔드 이런식으로 나뉘는데 각자 특기가 구분된다면 자투리 작업 (문서작업이라던가, 기타…)등을 두고 합의해야 한다.
-
서로의 수준이 비슷해야 한다.
누구는 잘하고 누구는 좀 어려운 상황이라면 공평의 추는 이동해야한다. 그리고 나의 파트와 관계가 없더라도 상대의 작업에 대한 높은 관심이 추가된다.
-
필요한 작업들을 (적어도 굵직한 작업 정도는) 빼놓지 않을 정도로 과제를 이해할 수 있어야 한다.
우리의 작업 정의 는 수월했으며 그 결과에 대해 이견이 없었다. 당일까지는…
일단 당장 다음날 jeounpar 님께 연락을 드려서 execve 의 실행방법에 대한 나의 몰이해를 토로하며 자료형을 수정해야 겠다고 말씀 드렸다.(이땐 자료형에 대해 서로의 스키마만 짜여있는 상태여서 괜찮았다.)
나는 이틀 뒤 또 다시 그 구조체를 뒤집어 엎었으며, 또 다음날 뒤집어 엎었다. 아마 jeounpar 님께서 애를 많이 먹으셨을 것 같다.
그리고 오늘도 PATH 를 어떻게 추가해야할지에 대해 서로 논의하며 구조체가 또 변경되었다.(이건 minor 한 수정이었다.)
execve 의 실행과 같은 중대한 부분에 충분한 정보 수집 없이 무작정 달려들었던 것이 이 혼란의 원인이었다.
큰 프로젝트에서 이랬으면 아마 팀단위 반목이 심했을 것이다.
팀프로젝트에 대한 느낀점은 나에 대한 성토의 내용이더라도 팀원에게 피해가 갈 수 있으므로 끝내겠다.
아무튼 팀원이 보살이다.
3.2. 코딩하면서 느낀점
포인터의 활용이 굉장히 많았다. 모든 함수에 전달되는 값에 Heap 메모리 주소가 빠지지 않았고, 모든 함수에서 또는 그것이 호출하는 함수에서 Heap 할당과 해제가 일어났다.
-
leak 에 대한 처리
예전부터 느껴왔던 것인데 leak 처리하는 것은 마치 노가다하던 시절 했던 바닥 방수 작업과 같은 느낌이 든다. 칠하고, 마르면 물 채워서 새는지 확인하고, 엘레베이터도 아직 안만들어진 아파트 몇 동을 소방호스 들고 오르락 내리락이다. leak 발생 여부를 완성되고 물을 넣기 전까지 알 수 없으며, 반복적이다. 42 코딩 컨벤션이 추가되어 25줄 내에 함수 기능과 leak을 처리해야된다? 창의력 대장이 될 수 있다. 25줄의 좁은 공간에 leak 경로를 모두 차단하며 컨벤션을 위반하지 않을 코드들을 가독성 있게 작성하는 작업은 진짜 고민을 많이 해야한다.
-
malloc fail 에 대한 처리
이건 더 힘들다. 지금까지 단 한번도 malloc fail을 경험해보지 못했다. malloc이 이루어지는 위치마다 메모리 할당 실패에 대한 처리가 이루어져야하고, malloc 실패시 그 메모리 공간을 활용하지 못함으로 인한 연쇄작용에 대해 함수 호출 스택을 따라 처리해야 한다. leak은 leaks 라는 명령어를 통해 발생 위치는 몰라도(m1 아키텍처는 sanitizer 지원이 안된다.) 발생 여부는 알 수 있는데 malloc fail은 유니콘처럼 보이지도 않는 유니콘과 같다.
malloc fail시 그냥 exit을 사용해서 종료해버리면 간단하긴하지만, 우리가 구현하는것은 shell 이다. 무슨일 있어도 최후의 보루처럼 굳건해야 하는 우리의 shell 은 exit이 요구사항에서 허용되었지만, 양심상 사용할 수 없는 그림의 떡이다. robustness!
이번 프로젝트에서 유난히 이런 부분들이 많아서 어떻게 코딩을 해야 할까 고민을 했고, 몇 가지 비법을 공유한다.
-
내부에서 malloc 을 사용하는 함수는 함수 호출되자마자 다른작업을 할게 아니라 malloc 부터 시도 해야한다.
이렇게 할 경우 만약 malloc fail이 일어나더라도 바로 함수 반환을 해버리면 malloc fail의 영향을 최소화 할 수 있다.
(반쯤 완성한 작업은 아예 하지 않은 작업보다 더 위험하기 때문이다.)
예시를 들어보겠다. linked list에 상태를 변경시키고, 노드를 추가하는 함수가 있다고 할 때, 일단 노드부터 malloc을 시도하는 것이다.
상태를 변경시킨 다음 malloc fail이 있다면 이 malloc fail을 어떻게 처리해야할지 감이 안잡힌다. 연관된 노드들을 모두 들어내야하나… 그냥 exit 해버릴까…여러번 malloc을 하는 함수일 경우 이 방법이 더 빛을 발한다.
node 를 추가하고 인자로 받은 string을 strdup 하여 node에 넣어주어야 할 경우 두 malloc을 연달아 실행하고 fail의 경우 아무 작업도 하지 않은척 반환해버리면 된다. -
해제를 전문적으로 하는 함수를 만들자.
말보다는 코드다.
// parse_safe_free_multi_str void *parse_safe_free_multi_str(void *ptr1, void *ptr2, void *ptr3, void *ptr4) { if (ptr1 != NULL) free(ptr1); if (ptr2 != NULL) free(ptr2); if (ptr3 != NULL) free(ptr3); if (ptr4 != NULL) free(ptr4); return (NULL); }// use t_cmd_redirection *add_cmd_redirection(t_cmd *cmd, int red_type, char *file) { t_cmd_redirection *ret; t_cmd_redirection *prev; char *str; ret = (t_cmd_redirection *)malloc(sizeof(t_cmd_redirection)); str = ft_strdup(file); if (ret == NULL || str == NULL) return(parse_safe_free_multi_str(ret, str, NULL, NULL)); ret->red_type = red_type; ret->file = str; ret->next = NULL; if (cmd->redirection_list == NULL) cmd->redirection_list = ret; else { prev = cmd->redirection_list; while (prev->next != NULL) prev = prev->next; prev->next = ret; } return (ret); } -
할당과 해제의 일관성
함수당 25줄 제한 이라는 무지막지한 코딩 컨벤션의 압박으로 strjoin을 커스텀하여 strjoin에서 인자로 받은 string들을 해제까지 한다면 strjoin을 호출한 함수에서 2줄의 여유공간이 확보되지 않을까? 라는 유혹들이 있었다. (꼭 strjoin이 아니더라도 많은 함수들에 그런 유혹이 있다.)
이렇게 하면 일단 가독성이 떨어진다. 해당 함수의 역할에 대해 정확히 가늠하기 어려워진다. 설명받는 제 3자에게도, 코딩하는 본인에게도.
그리고 malloc fail에 대한 방어가 어려워진다.
예를 들어 커스터마이징한 strjoin에서 malloc fail이 발생할경우
-
그냥 NULL 을 반환하고 종료한다.
그럼 호출한 함수에서 NULL 일 경우 string 2개를 free 해주라는 명령이 추가된다. (2줄 줄이려다 3줄이 추가된다. braket 포함 5줄 까지…)
-
string 2개를 free 시켜주고 NULL을 반환한다.
strjoin을 호출한 함수에서 malloc fail을 통보받고, 기존 상태를 복구할 방법이 없어진다. malloc fail 발생시 최대한 영향을 최소화 해야하는데 이것도 아니고 저것도 아닌 하다가 팽개친 상태가 만들어진다.
최대한 malloc free는 malloc을 사용한 함수 내에서, 또는 그 데이터를 사용하는 함수들 중 호출스택 최상위에 있는 함수에서 해제하는 일관성을 유지해야한다. (근데 솔직히 25 줄 제한 때문에 몇 번 타협했다…)
-

There are currently no comments on this article
Please be the first to add one below :)
내용에 대한 의견, 블로그 UI 개선, 잡담까지 모든 종류의 댓글 환영합니다!!