개요
-
프로젝트 이름
Fit Mate: 개인 맞춤형 운동을 위한 헬스케어 서비스
-
내용
기존의 FitMate에서 프론트 페이지 리뉴얼과 기능적 개선, 백엔드 서버의 비기능적 퍼포먼스 향상을 시도한 프로젝트
-
플랫폼
Web Application
-
제안 배경
a. 기존 프로젝트의 프론트 페이지 디자인 개선 필요
b. 기존 프로젝트가 기능적인 구현에만 집중한 관계로 안정적인 배포환경을 조성하지 못했음
c. JWT, Radis 등 다양한 기술들을 활용해보는 경험 -
기존 프로젝트 대비 주요 변경 사항
a. 팀 개편: 프론트엔드 2명, 백엔드 2명, 디자인 2명 (총 6명)
b. 프론트 디자인 적용
c. 프론트 페이지 다시 구현
d. 체성분 변화 기록과 추천 기록 기능 축소
e. 내 운동, 내 보조제로 플레이리스트 처럼 운동 루틴 관리할 수 있는 기능 추가
f. 백엔드 서버 비기능적 요구사항에 대한 완성도 제고
구현한 코드는 다음 GitHub Page에 가면 확인할 수 있다.
진행 기간
2023.07 ~ 2023.09
소감
먼저 좋은 점부터… 디자인 팀이 있고, 프론트를 할 줄 아는 팀원이 있으니 확실히 결과물이 달라보였다. 지난번 프로젝트에서 디자인 회의는 정말 주먹구구 식이었지만, 이번 프로젝트의 디자인 회의는 figma라는 디자인 툴을 가지고 이부분은 픽셀이 어떻고 플로팅을 어떻게 하고, 호버 모션은 또 어떻고… 디자인이 뭔지, UX를 어떻게 고려해야 하는지 아는 팀원들이 많아서 아이디어를 내고 설득하는게 신났다. 그리고 그 과정에서 UI/UX 적인 부분에 대해서 많이 배운 것 같다. 프론트도 마찬가지다. 다소 복잡한 아이디어를 제안해도 그것을 어떻게 구현해야 하는지 경험이 있는 분이 계셔서 회의에서 아이디어 교환이 원활했던 것 같다. 백은 지난 프로젝트랑 동일하게 더할 나위 없었던 것 같다.
아쉬운 점으로는…
생각보다 진행이 더뎌서 아쉬웠다.
이전 프로젝트는 맨땅에서부터 시작하는 거였지만, 이번 프로젝트는 실행가능한 레퍼런스가 프론트와 디자인에게 주어졌다.
여기에 더해 이전 프로젝트의 결과물을 시연하고 설명하고 질문 받고, 작성했던 보고서, ppt, api list 들을 새로 참가한 팀원들에게 모두 주었다. 디자인 측에서 기능들을 누락한 일이 몇번 있었다. 그 중 몇 개는 프로젝트 일정상 도저히 구현할 수 없게 되어버리는 것도 있었다. 결과물은 정말 훌륭했지만 그 과정에서 디자인이 확정되지 못하고 자꾸 변경되었기 때문에 프로젝트 일정이 연장되었다고 생각한다. 그리고 프로젝트 마감 예정기한 2주 전에 새로운 기능이 제안되었기 때문에 결국 총 3주가 연장되었다.
처음 겪는 프로젝트 마감 연장이다. 왜 그랬을까? 난 뭘 했어야 했을까… 회의가 부족했던것 같기도 하다. 우리(프로젝트 원년 멤버인 지성과 나)는 프론트와 거의 실시간으로 소통하며 작업을 했다. 오류가 의심되거나 궁금한 점이 있다면 언제든지 카톡방에 질문을 남겼고, 30분 내에 원인 파악과 향후 어떻게 할 것인지에 대해 답변이 달렸다. API는 문서로 남겼고 지속적으로 업데이트 되었다. 그러나 백과 디자인은 아니었다. 가끔 figma 를 보고 디자인 오류에 대해 질문하는게 거의 다였고 일주일에 한번 있는 전체 회의에서 소통 다운 소통을 했다. 그런데 이게 이상한 것은 아니라고 생각한다. 디자인은 프론트와 원활하게 작업해야 한다고 생각한다. 디자인의 요구사항은 거의 프론트에서 구현이 필요한 것이었고, 백 또한 디자인에 기능적으로 어떻게 해달라 요구할 거리가 잘 없었다. 아무튼… 조금 디자인에 관심을 가졌어야 했었다.
부하테스트
테스트 배경
FitMate 서버 애플리케이션의 개발은 두 번의 개발 프로젝트를 통해 개발되고 향상되었다. 2023.03부터 2023.7월까지 진행된 1차 프로젝트는 기능적인 요구사항을 충족하는 것을 주안점으로 하는 프로젝트였으며 성공적으로 개발을 완료한 뒤 본인 소유의 NAS 상에 도커를 활용하여 배포 환경 조성과 배포가 이루어졌다. 2023.07부터 2023.09까지 진행된 2차 프로젝트는 서비스의 UX/UI 리뉴얼에 맞추어 변경된 기능적 요구사항을 업데이트하고 여러 비기능적인 요구사항 충족을 통해 SW의 품질을 향상하는 것이 목표였다. 2차 프로젝트가 완료된 지금, 1차 프로젝트의 결과물인 단일 컨테이너로 구성되었던 서버와 새로 개발한 Kubernetes 분산 서버와의 성능 비교를 위해 본 테스트를 계획하였다.
서버의 구조
프로젝트에서 개발한 서버의 아키텍처를 간단히 표현하면 다음과 같다.
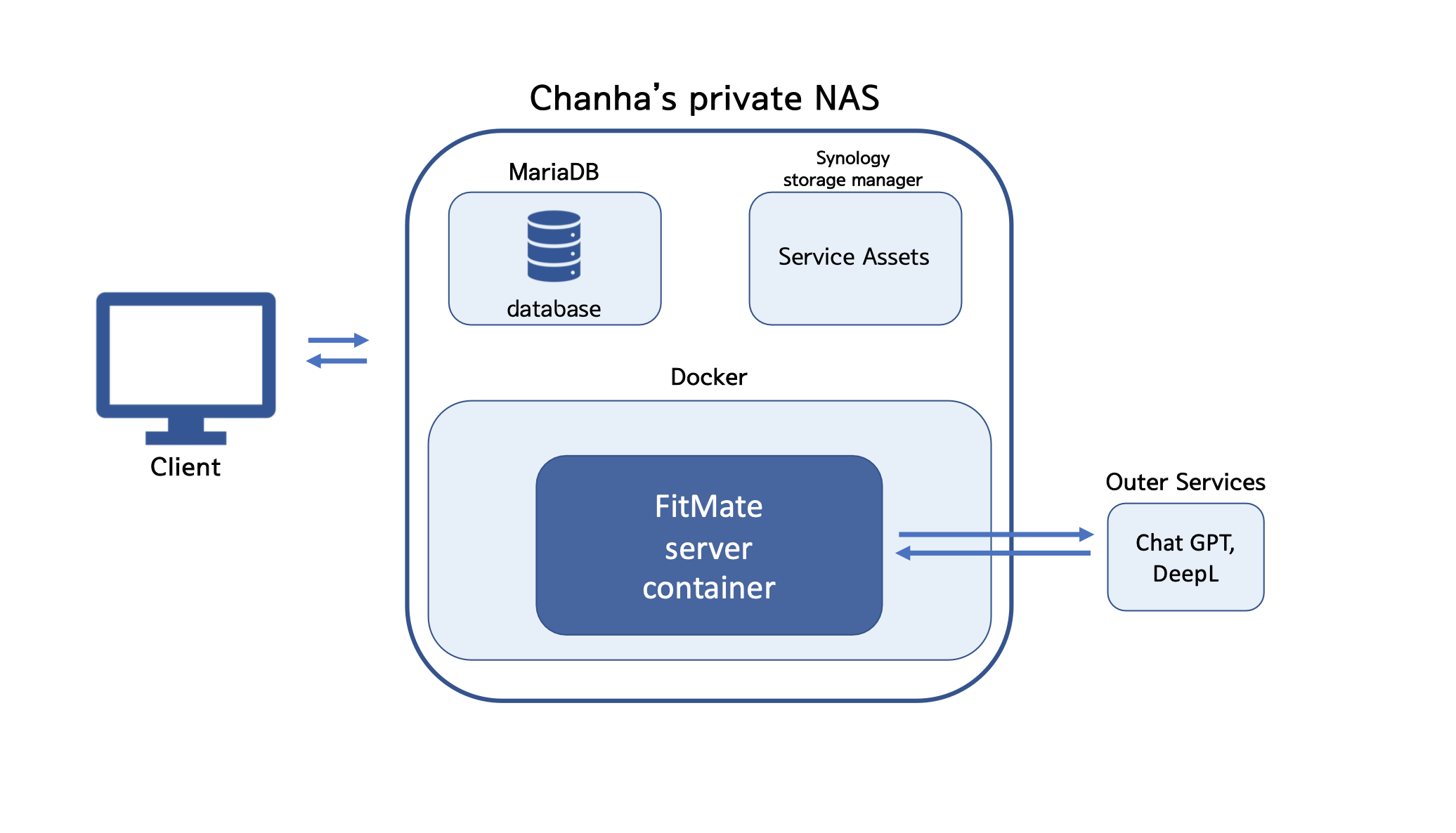
NAS에 MariaDB, Docker를 설치하고 개발된 서버를 배포하였다. 모든 서비스 백엔드의 구성요소가 온프레미스 방식으로 한대의 물리적인 NAS 머신에 집약된 구조이다.
2차 프로젝트에서 개발한 서버의 아키텍처는 다음과 같다.
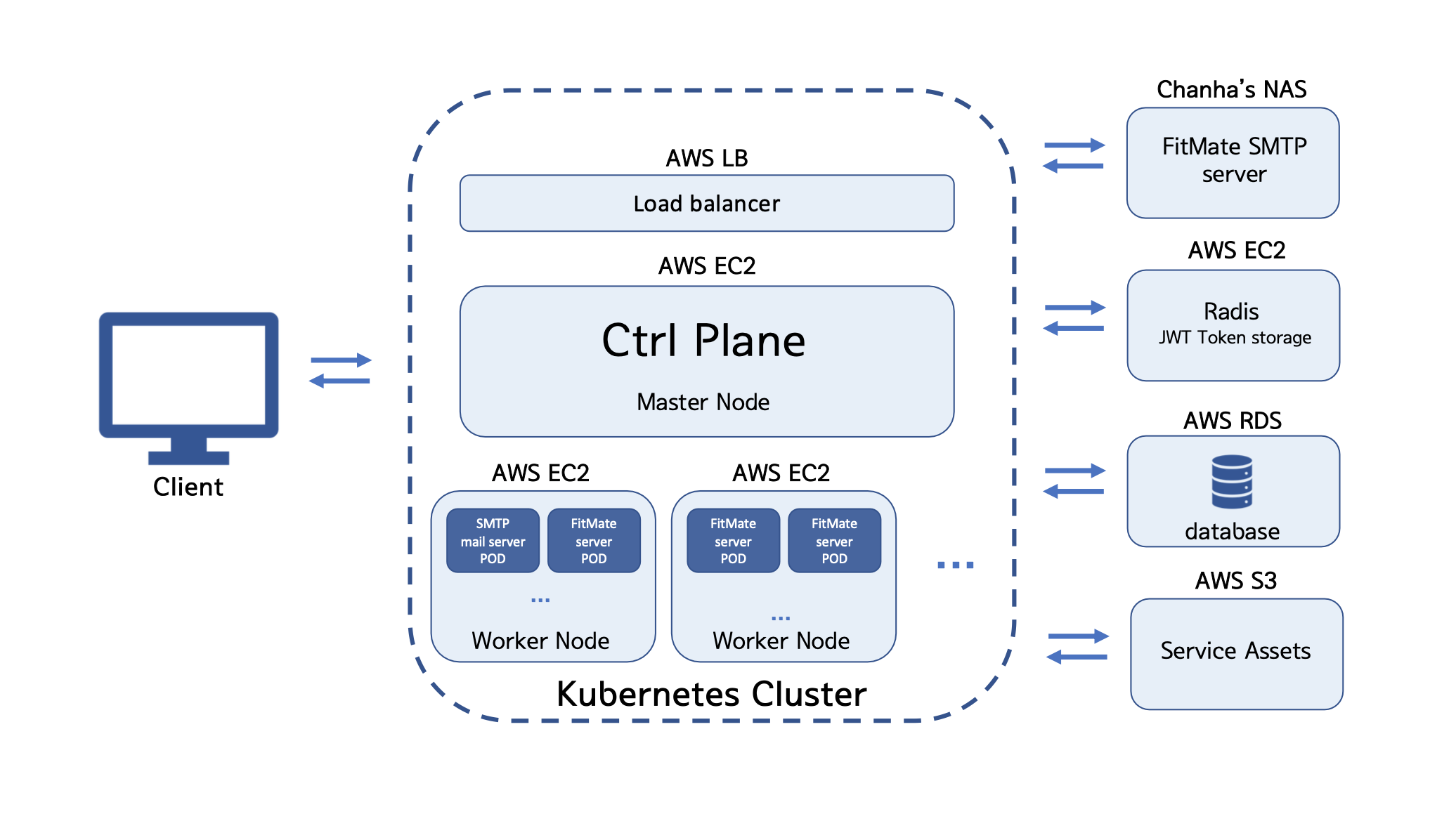
1차와 달리 2차에서는 Kubernetes cluster 구축을 위해 여러 대의 노드 머신들이 필요했고, 이러한 요구사항은 NAS의 제한적인 하드웨어 자원으로는 구현이 불가능했다. 따라서 서비스의 기반을 AWS cloud로 이전한다는 결정을 내렸다. 2차 프로젝트에서는 이용자 메일 인증 기능이 추가되었는데 여기서 이용자 계정 생성 시 메일 인증을 위해 필요한 SMTP 서버는 Synology 사의 NAS 기반 SMTP 서비스를 활용하기 위해 NAS에 구축되었다. 하지만 서비스 내에서 FitMate 메인 백엔드 서버와 통신하며 인증 번호를 생성하고 이를 NAS SMTP에게 유저 주소로 전송을 명령하는 서버가 따로 필요하기 때문에 그러한 역할을 하는 서버를 클러스터 내에 따로 만들어 놓았다. 클러스터 내에 SMTP 서버는 트래픽이 많지 않을 것으로 예상하여 1개의 pod만 생성하도록 했고, 오토 스케일링이 적용되지 않는다. FitMate의 메인 백엔드 서버가 존재하는 pod의 경우 pod의 부하에 따라 2개에서 5개까지 스케일아웃될 수 있도록 오토 스케일링 규칙을 적용했다. 클러스터 외부에는 상술한 메일 인증 기능을 위한 SMTP 서비스가 존재하고, 메인 서버 pod에서 발급되는 JWT 토큰과 자주 사용되는 서비스 데이터를 보관하는 Radis 서버가 존재한다. 그 외에 서비스 데이터를 저장하는 AWS RDB, AWS S3 서비스가 존재한다.
테스트 설계
테스트 환경
-
Kubernetes Cluster
-
EC2 Node (1 Master Node, 2 Worker Nodes)
t3.small: 2 vCPU, 2 GiB memory, Ubuntu 22.04
-
Pod (2 ~ 4 Pods)
limits: 500m CPU, 512MiB memory
requests: 400m CPU, 400Mib memory
-
-
Single server A
t3.small: 2 vCPU, 2 GiB memory, Ubuntu 22.04
-
Single server B
t2.micro: 1 vCPU, 1GiB memory, Ubuntu 22.04
Testing Tool
-
Apache Jmeter 5.6.2
API 요청 생성 및 TPS 측정 도구
-
Kubernetes Metrics
Kubernetes Cluster 의 Node와 Pod 상태 관제
-
Docker Metrics
단일서버의 Container 상태 관제
테스트에 활용할 API
테스트에서는 각 서버의 퍼포먼스를 검증하기 위해 서비스의 3가지 API를 활용할 예정이다.
A. 단순히 데이터를 읽는 작업 API (Read)
-> GET /user/private
B. JOIN이 많은 작업 API (Join)
-> POST /supplements/search/list/{pageNum}
C. DB write 작업 API
-> POST /myfit/routines/supplement/{supplementId}
각각의 API를 수만에서 수백 만회 실행하며 평균 TPS를 살펴보겠다.
테스트 계획
-
Test A
2개의 Pod가 동작 중인 Kubernetes Cluster와 단일서버 A를 대상으로 3가지 API를 실행한다. 이때 각 API를 지속해서 호출하는 500명의 유저(쓰레드)를 300초에 걸쳐 생성한다. 300초가 지나 유저가 모두 생성된 뒤를 기준으로 TPS를 관측한다.
-
Test B
2개의 Pod가 동작 중이고 Pod의 부하에 따라 4개까지 증가하는 Kubernetes Cluster와 단일서버 B를 대상으로 3가지 API를 실행한다. Test A와 동일하게 500명의 유저(쓰레드)를 300초에 걸쳐 생성한다. 300초가 지나 유저가 모두 생성된 뒤를 기준으로 TPS를 관측한다.
테스트 결과 분석
Test A 결과
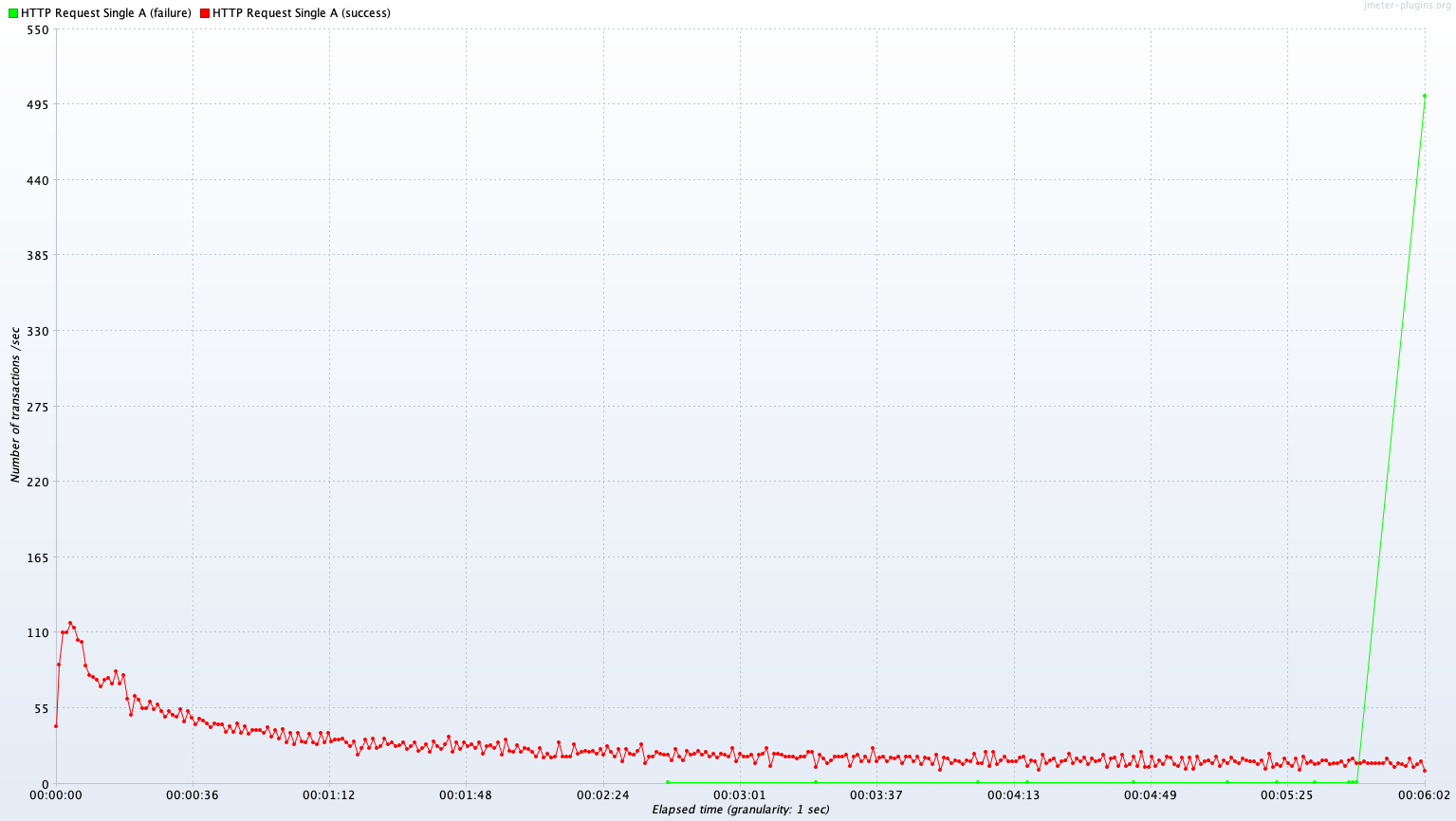
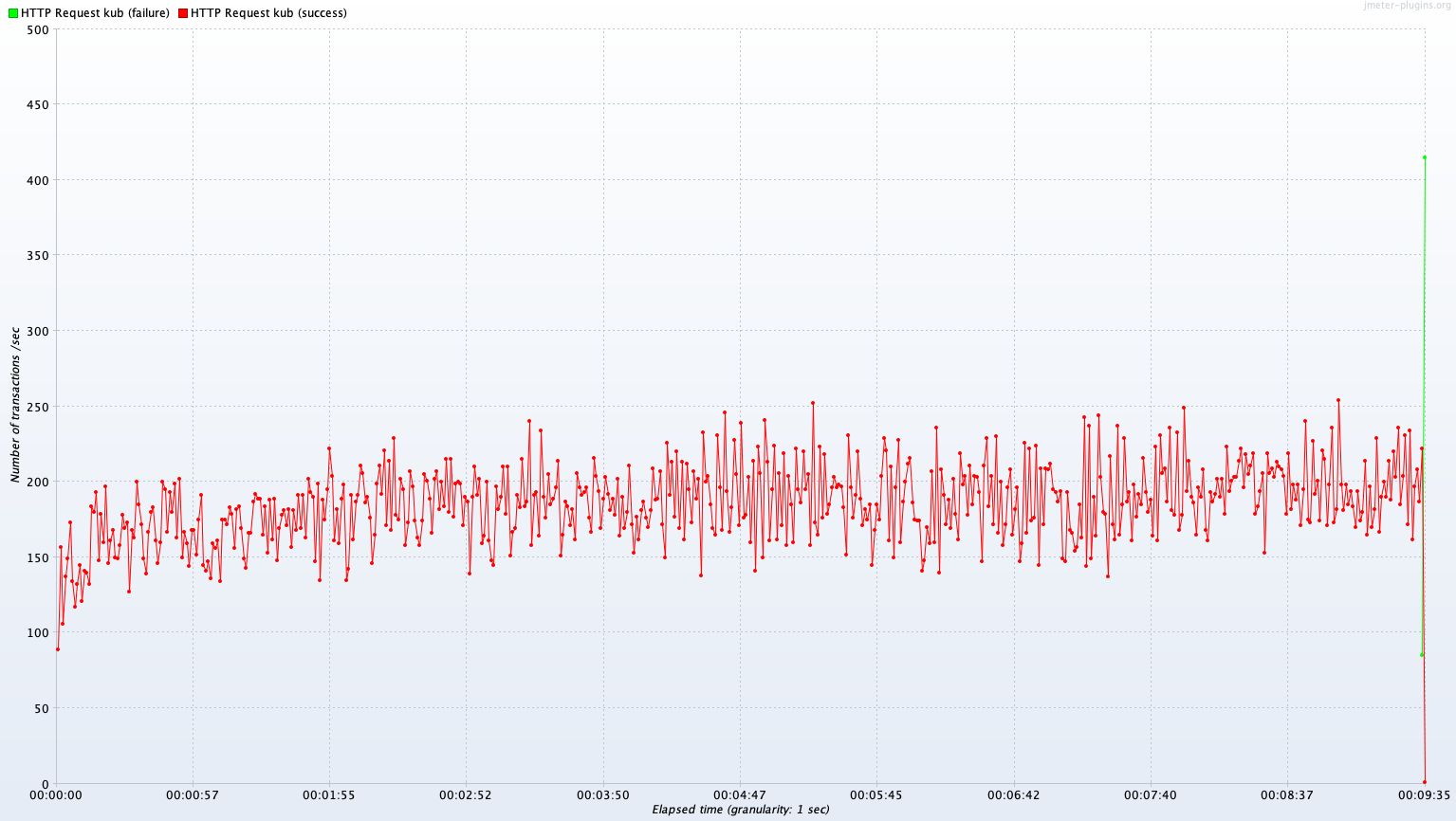
Single Server A vs Kubernetes Cluster (2 Pods)
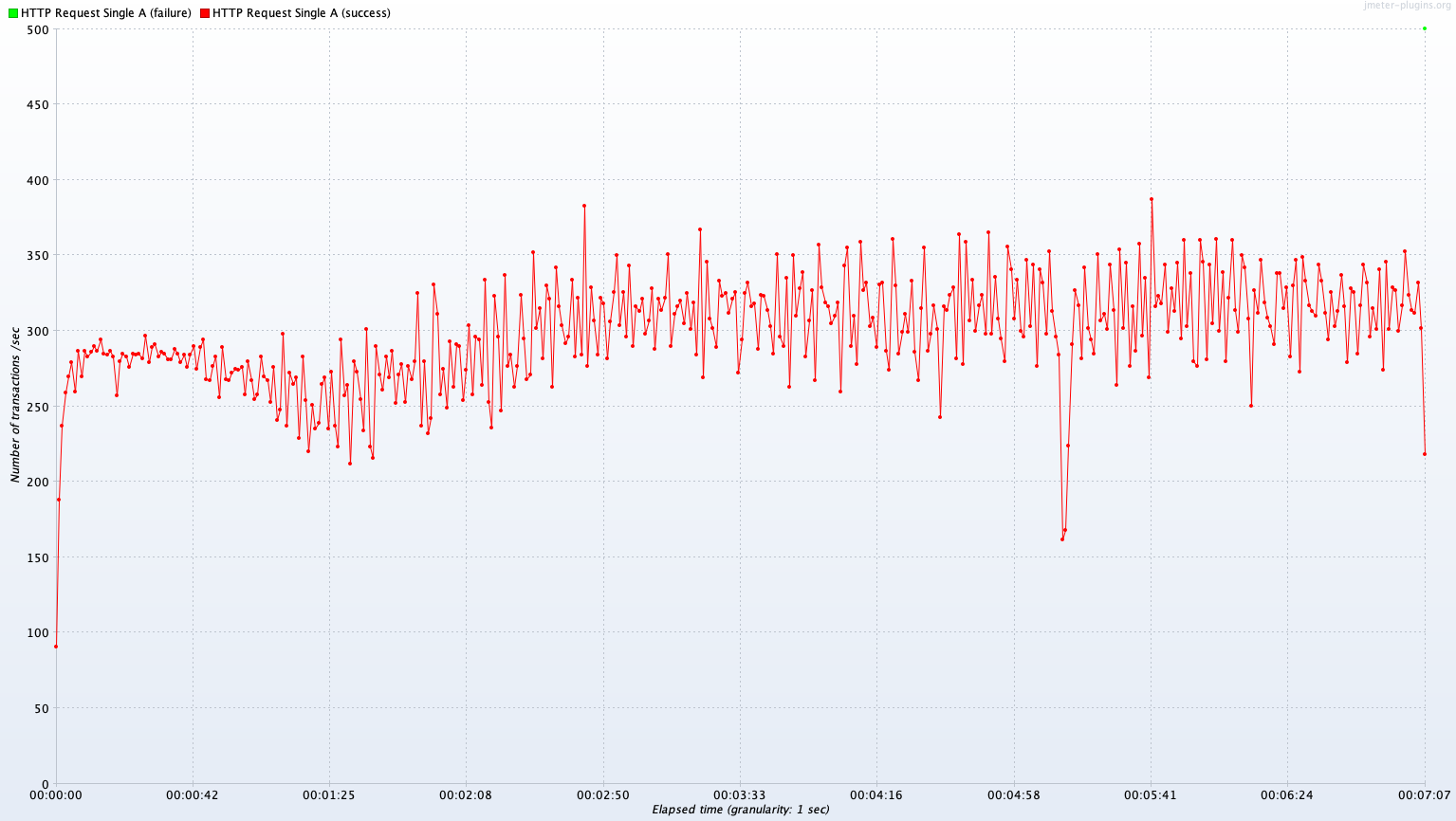
Avg TPS after 300 sec: 313.9 TPS
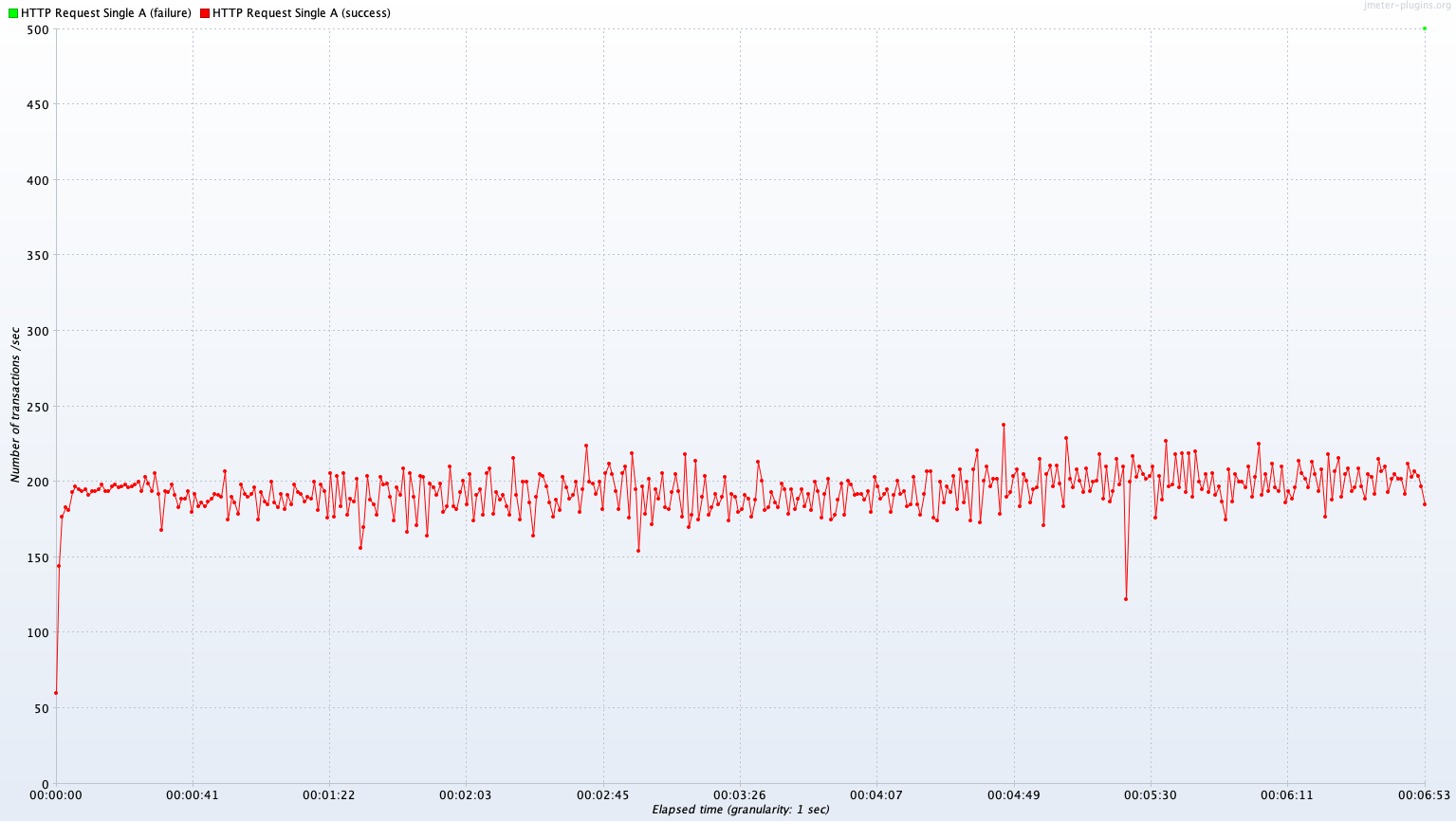
Avg TPS after 300 sec: 200.8 TPS
Avg TPS after 300 sec: 15.5 TPS
Avg TPS after 300 sec: 191.8 TPS
Avg TPS after 300 sec: 183.2 TPS
Avg TPS after 300 sec: 8.0 TPS



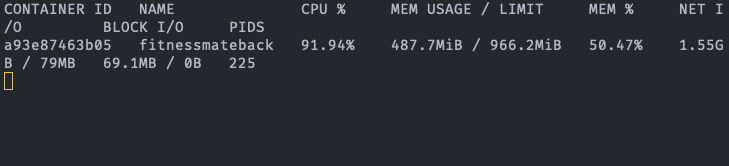
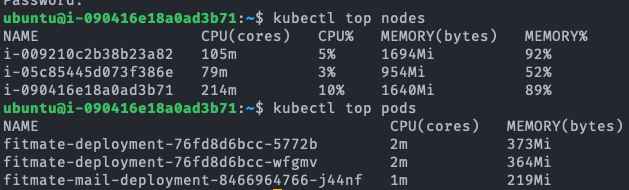
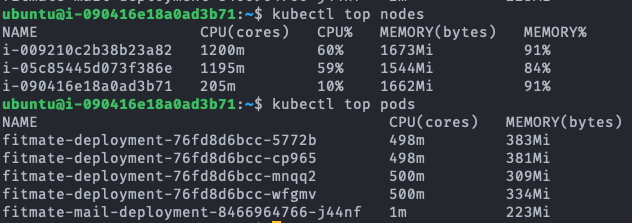
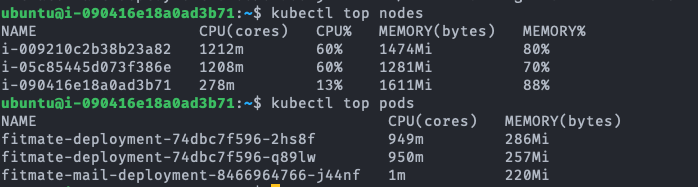
fitmate-deployment-.... 가 서버의 pod이다.
Test A 결과 분석
Avg TPS after 300 sec
| Read | Join | Write | |
|---|---|---|---|
| single A | 313.9 TPS | 200.8 TPS | 15.5 TPS |
| Kubernetes Cluster(2 Pods) | 191.8 TPS | 183.2 TPS | 8.0 TPS |
(Single - Kube) / Single
| Read | Join | Write | |
|---|---|---|---|
| (Single - Kube) / Single | -38.9% | -8.8% | -48.5% |
먼저 TPS 측정 결과를 보면 Kubernetes cluster가 서버(Pod)가 2개 병렬이기 때문에 더 높은 TPS를 보여줄 것으로 기대했지만, 실제 결과는 Single A 서버가 Kubernetes cluster 서버보다 모든 측정 항목에서 더 높은 TPS 퍼포먼스를 보인다. 이에 대해 2가지 원인이 예상된다.
- Kube cluster의 로드밸런서의 처리 한계로 인한 병목현상
- 서버 자체의 오버헤드로 인한 Pod 자원 부족
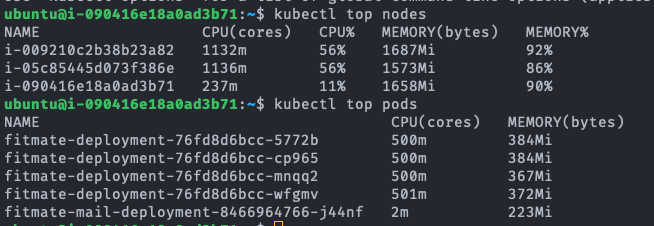
첫 번째 로드밸런서는 우리 서비스가 AWS의 상용 로드밸런서를 사용하고 있었기 때문에 이정도의 부하를 견디지 못할 확률은 매우 낮아 보였다. 더군다나 이어서 있는 테스트에서 클러스터가 이것보다 나은 퍼포먼스를 보여줬기에 로드밸런서가 원인일 확률은 매우 낮다. 때문에 두 번째 원인인 Pod 내 자원 부족으로 인한 병목현상에 초점을 두고 서버를 모니터링해 보았다. 먼저 Idle 상태의 Single A 서버의 컨테이너를 보면 0.1%대의 매우 낮은 CPU 점유율과 42%의 높은 메모리 점유율을 보여준다. 테스트 시작 후 300초가 경과한 시점에서 CPU 점유율은 71%로 극적인 상승을 보이지만, 메모리 점유율은 거의 변동이 없다는 것을 확인할 수 있다. Kubernetes Cluster의 경우 Idle 상황이든 테스트 상황이든 메모리 사용률이 높지만 maximum 값에 달하지는 않는 반면, CPU의 경우 테스트 상황에서 100% 사용된다. 자원의 총량은 단일 서버 환경과 분산서버 환경이 같지만, 서버가 기본적으로 동작하기 위해 필요한 CPU 자원이 분산서버 Pod의 0.5 Core 자원 상한 환경에서 페널티로 작용했을 것이다. 이에 대해서는 후속적인 테스트를 통해 가설을 검증해 보겠다.
그 외에 Write 연산에서 두 서버 모두 시간 경과에 따라 퍼포먼스가 저하되는 것을 확인할 수 있다. 이는 DB 서버의 I/O가 병목의 원인으로 보인다. 이는 뒤에서 Test B의 결과와 함께 조금 더 자세히 분석해 보겠다.
Test B 결과
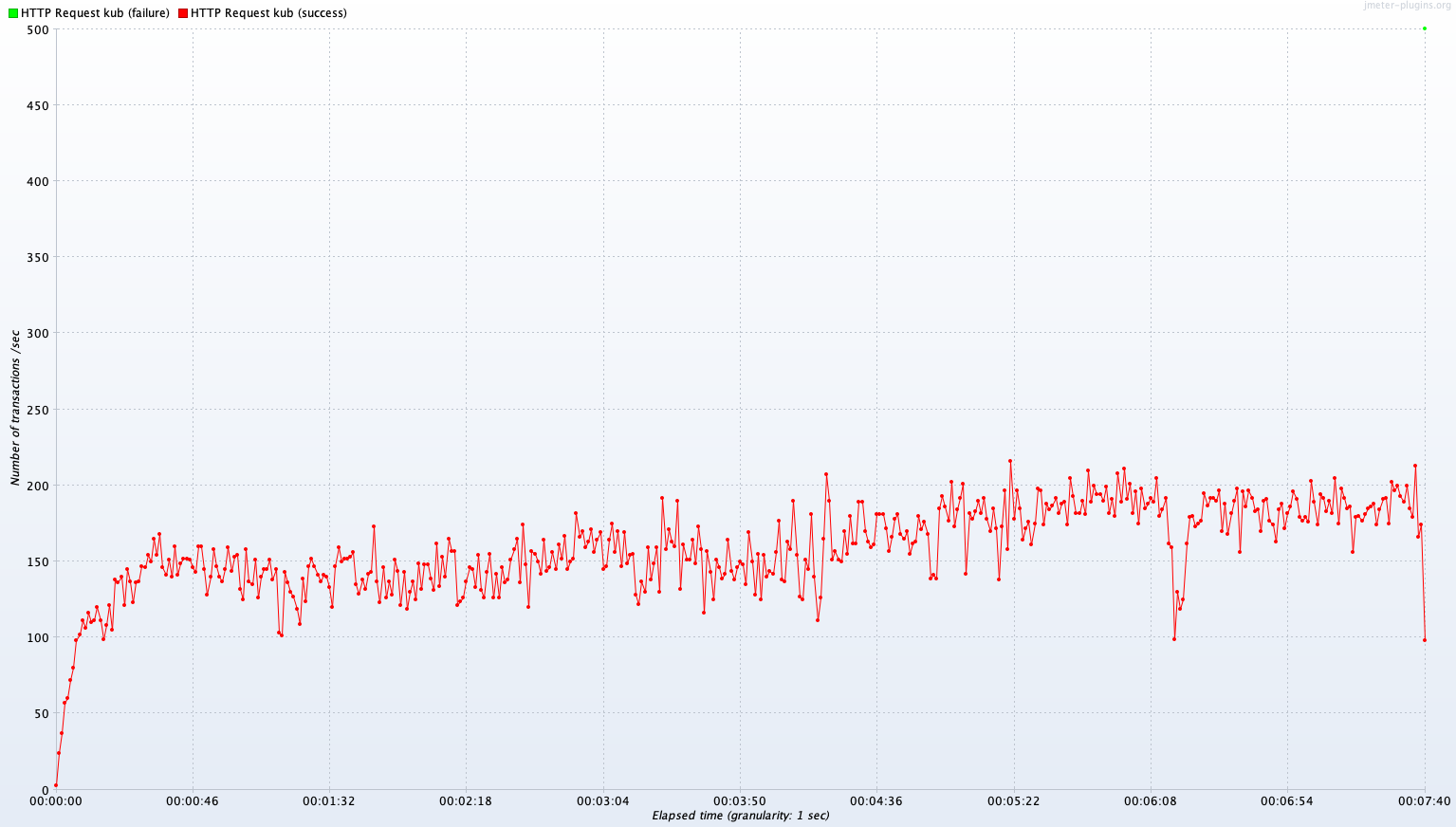
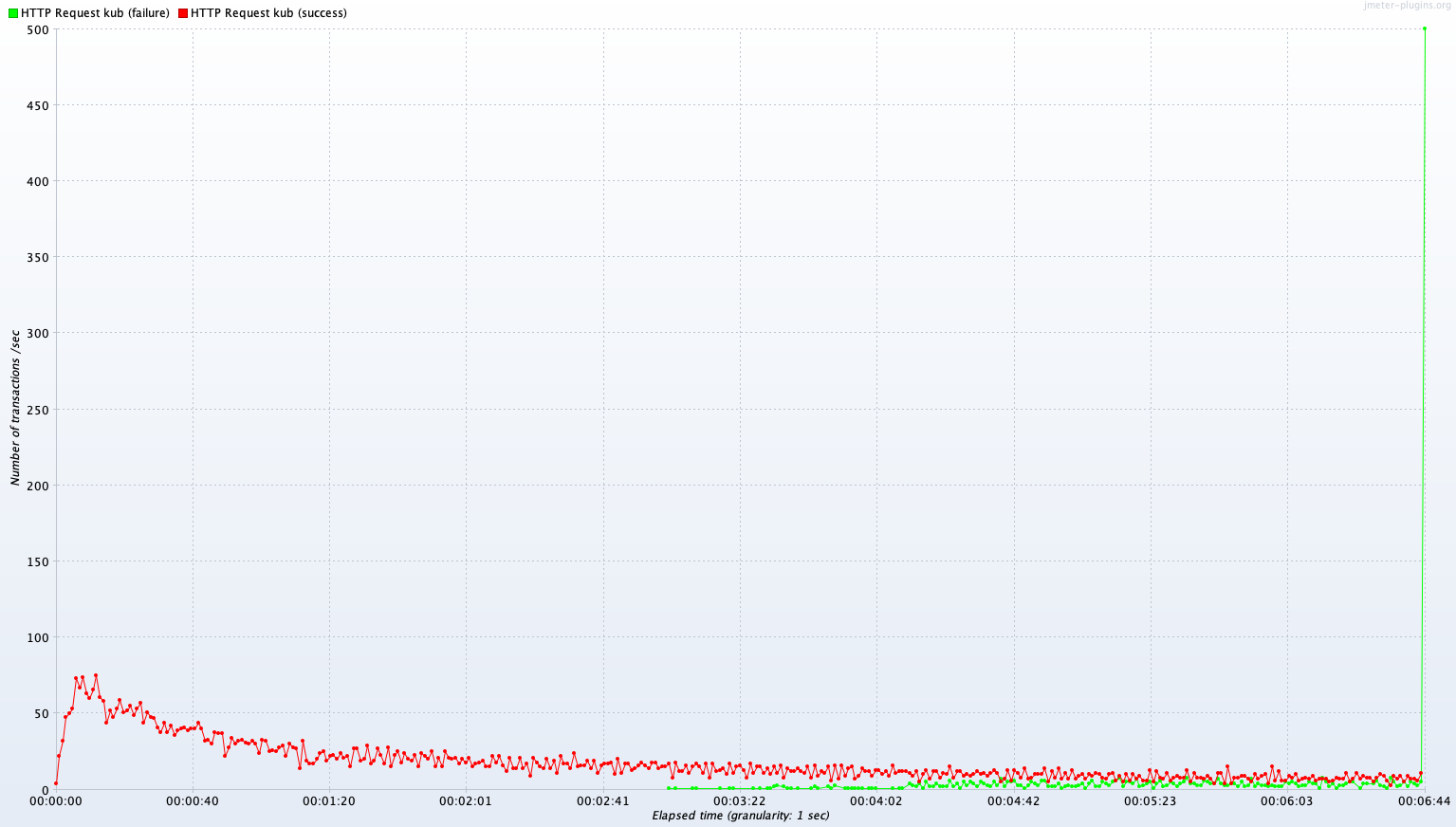
Single Server B vs Kubernetes Cluster (2~4 Pods)
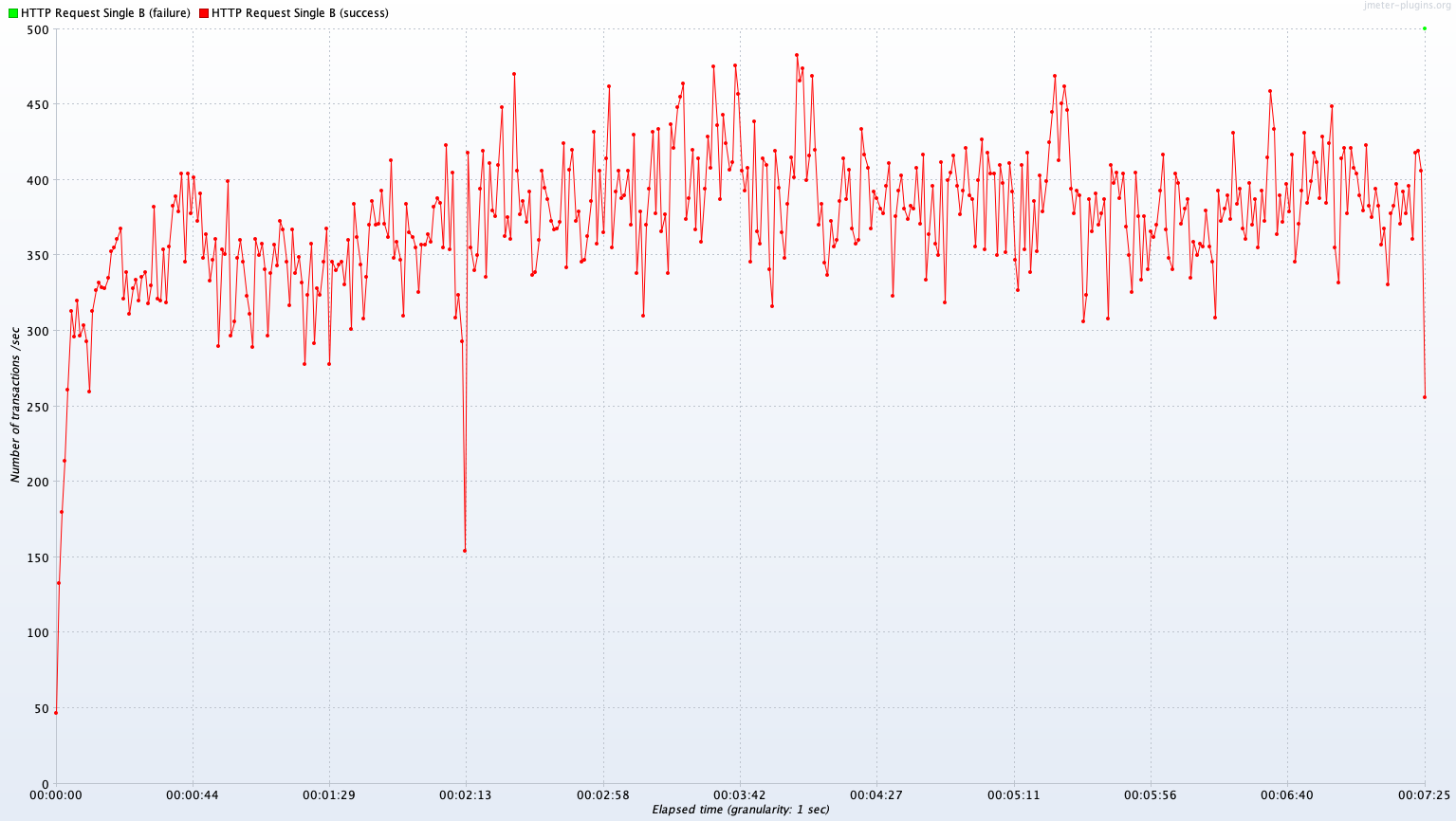
Avg TPS after 300 sec: 385.1 TPS
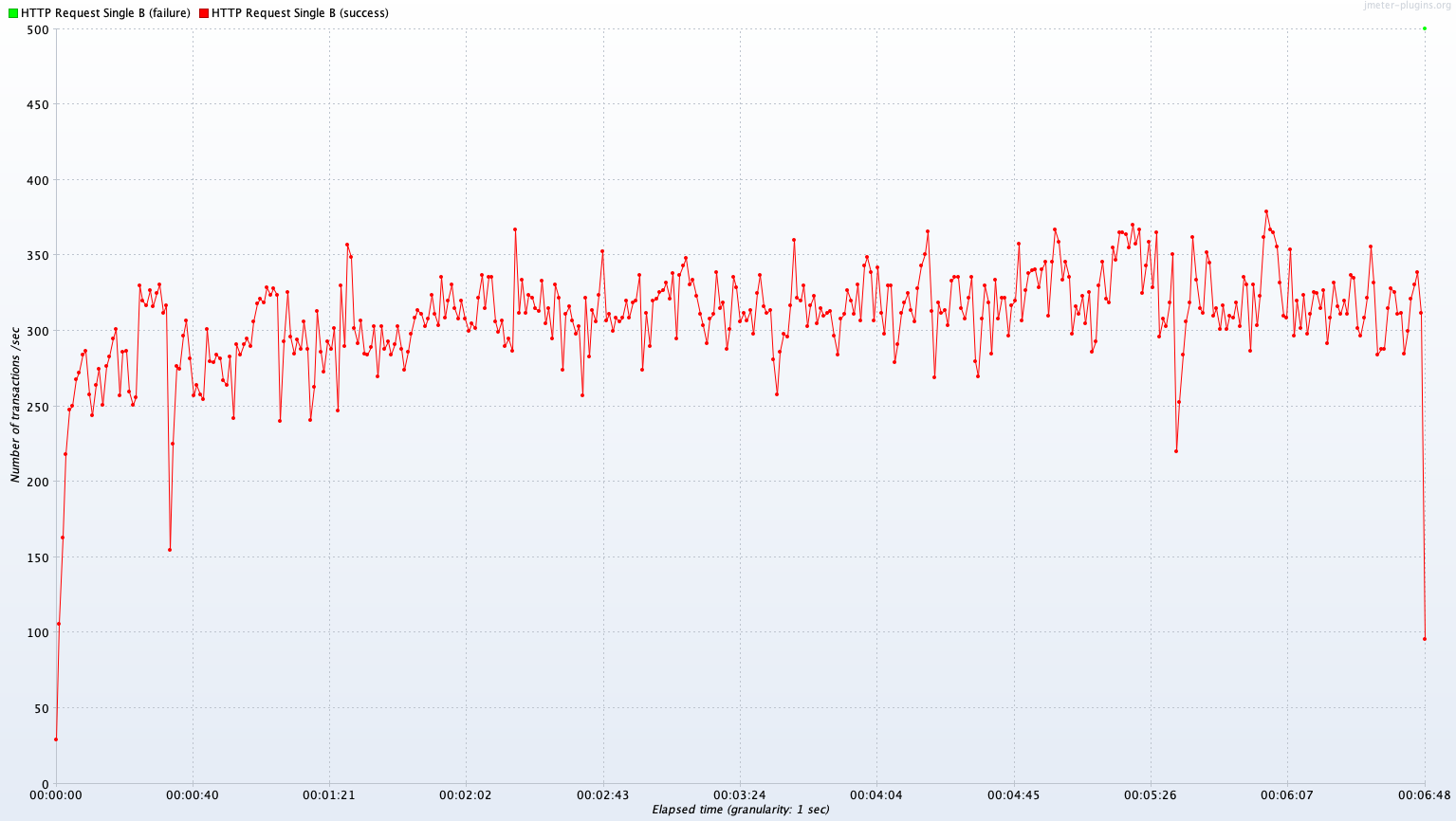
Avg TPS after 300 sec: 322.4 TPS
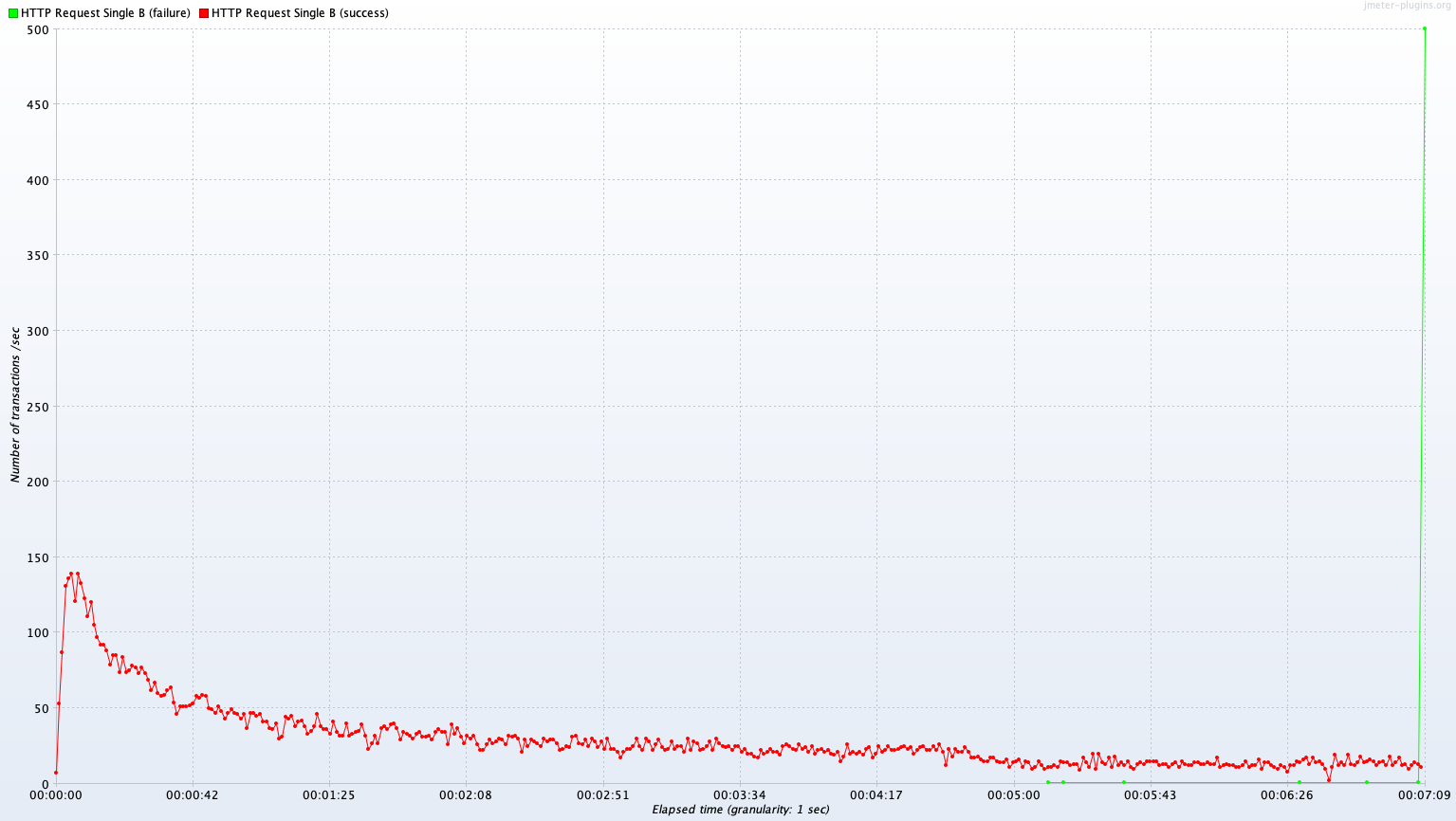
Avg TPS after 300 sec: 13.2 TPS
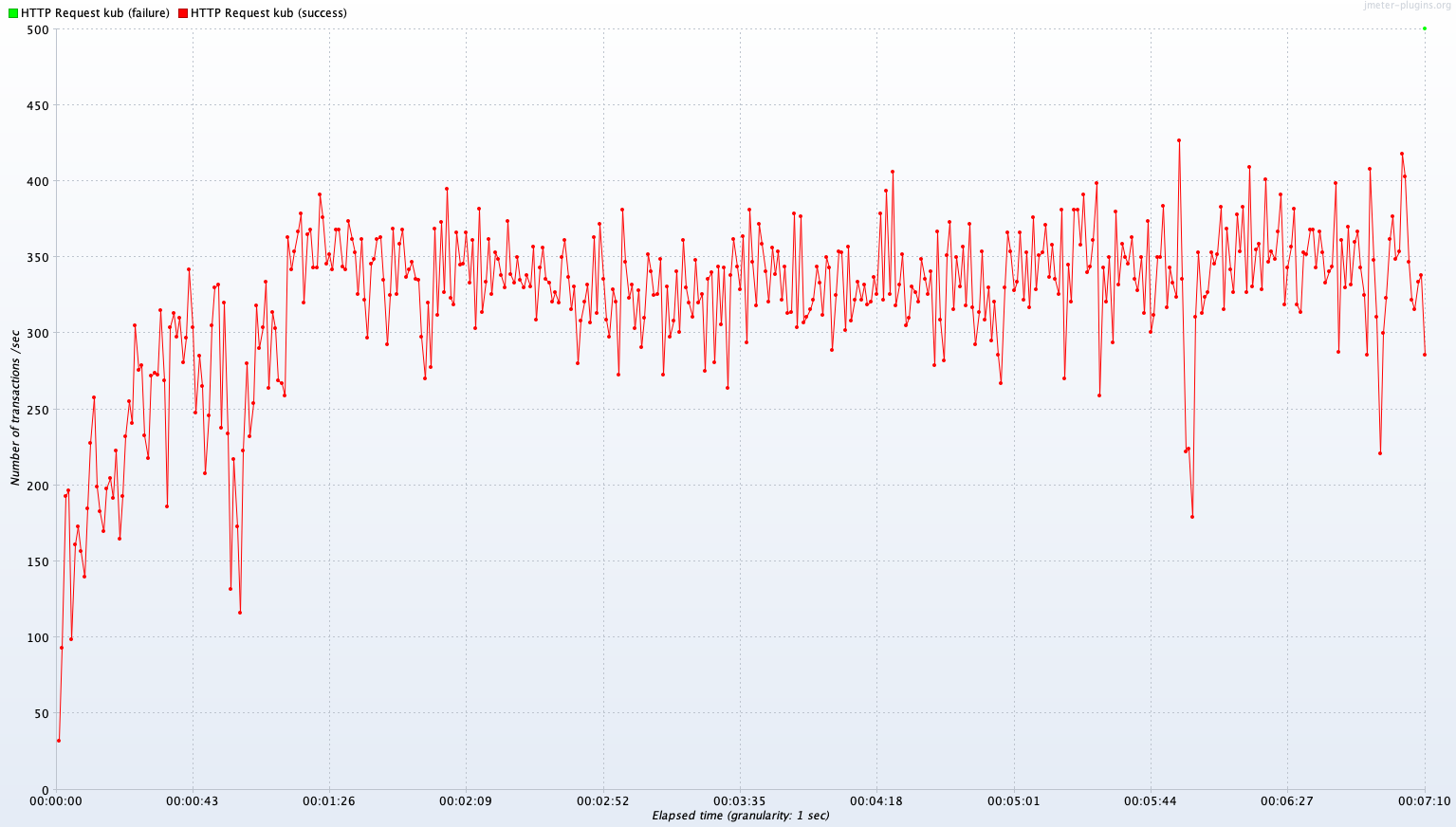
Avg TPS after 300 sec: 343.0 TPS
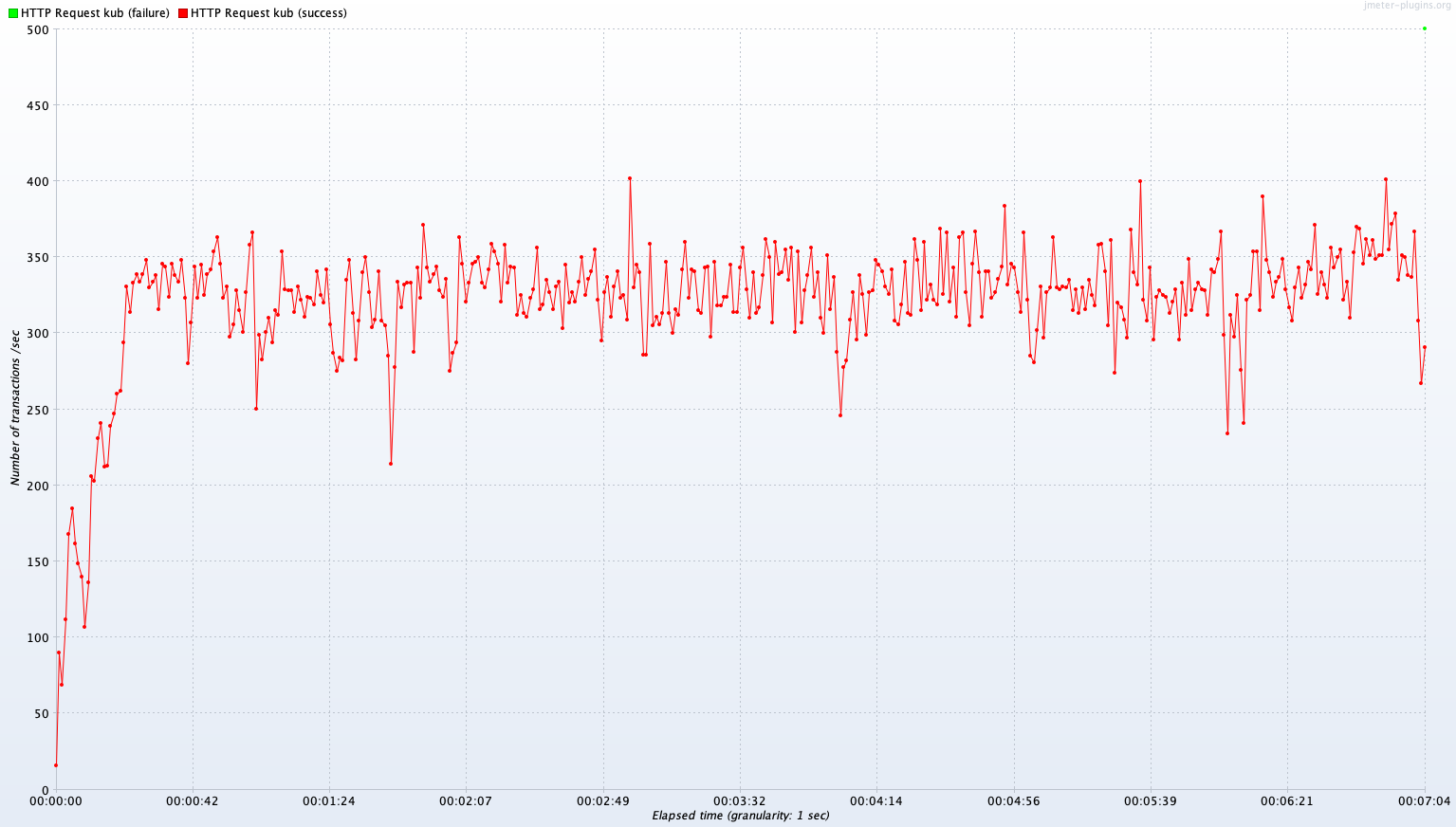
Avg TPS after 300 sec: 334.3 TPS
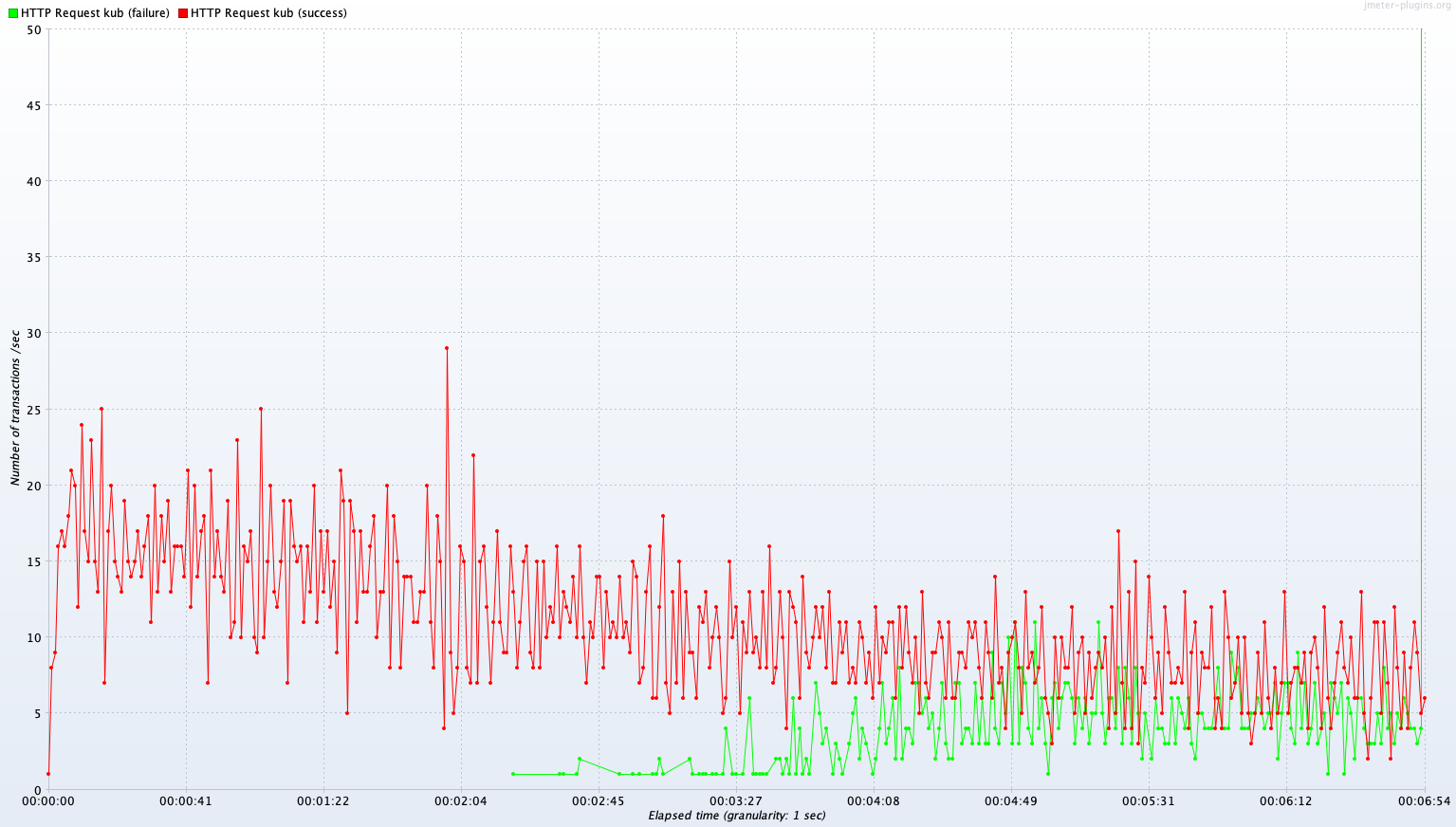
Avg TPS after 300 sec: 7.8 TPS




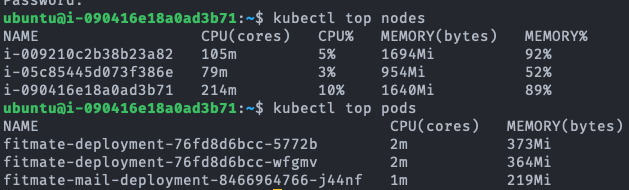
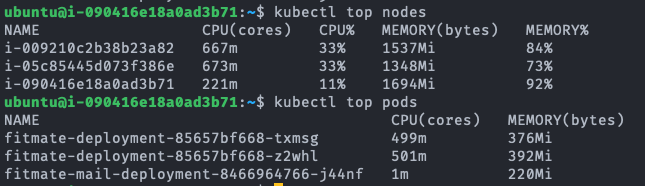
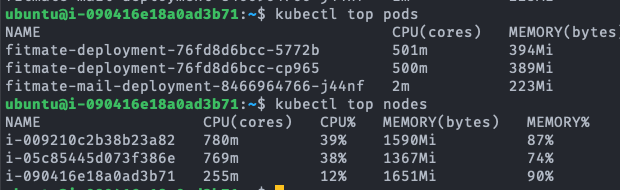
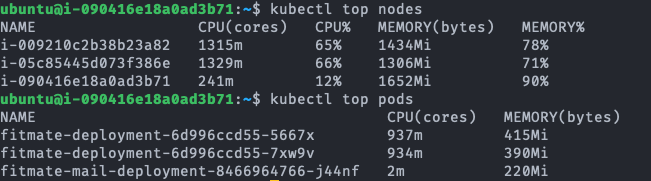
fitmate-deployment-.... 가 서버의 pod이다.
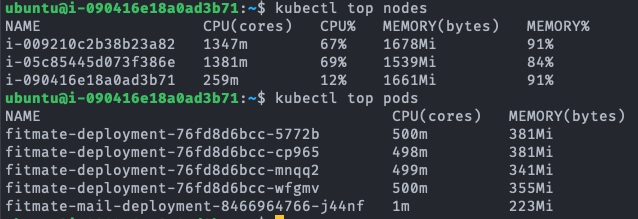
Test B 결과 분석
Avg TPS after 300 sec
| Read | Join | Write | |
|---|---|---|---|
| single A | 385.1 TPS | 322.4 TPS | 13.2 TPS |
| Kubernetes Cluster(2~4 Pods) | 343.0 TPS | 334.3 TPS | 7.8 TPS |
(Single - Kube) / Single
| Read | Join | Write | |
|---|---|---|---|
| (Single - Kube) / Single | -10.9% | 3.7% | -40.9% |
Test A와는 달리 영역별로 TPS 성능 우위가 다르다. 단순 DB read의 경우 Kubernetes Cluster가 Single B보다 10.9% 낮은 TPS를 보여주지만, Join 연산이 많은 경우 Kubernetes Cluster가 Single B에 비해 3.7%로 아주 근소하게 높은 TPS를 보여준다. Write는 Kubernetes Cluster가 Single B보다 40.9% 낮은 성능을 보인다.
이에 대해 좀 더 정확한 분석을 하려면 Test A의 결과와 비교해 보아야 한다. 먼저 Test B는 Test A와 비교해 자원(CPU, memory)의 총량이 2배인 서버 환경에서 진행되었다. 단일 서버에 대해 스케일 업(HW 성능 향상)이 있었고, 분산 서버에 대해서는 스케일 아웃(Auto scaling을 통한 Pod 증가)이 있었다. 이 때문에 두 서버 모두 퍼포먼스가 있을 것이라고 예상할 수 있겠지만, 다음 표에 나와 있듯 꼭 그렇지만은 않다.
TPS difference between Test A and B
| Read | Join | Write | |
|---|---|---|---|
| single A, single B | 22.7% | 60.6% | -14.8% |
| Kube Cluster 2Pod, 2~4 Pod | 78.8% | 82.3% | -2.5% |
Write에서 두 종류의 서버에서 모두 소폭의 퍼포먼스 하락이 있었고, Read와 Join에서 퍼포먼스 향상이 있었다.
Read의 경우 단일 서버에서 CPU 자원이 2배로 향상됐음에도 TPS 22.7% 향상되는 것에 그쳤다. 그런데도 status를 확인해 보면 CPU는 100% 모두 사용하고 있는 것을 확인할 수 있다. 예상되는 원인으로는 Read의 측정을 위해 사용하는 GET:/user/private API는 요청 헤더로 전달한 JWT 토큰에서 User ID를 해석하고 이 User ID를 이용해 DB에 저장된 User 정보를 읽어서 반환하는 과정으로 처리가 진행된다. 여기서 JWT 토큰으로부터 User ID를 해독하는 과정이 SHA-256 암호를 복호화하는 과정인데 SHA-256 복호화가 아무리 빠르다고 한들 CPU에 가해지는 부담을 무시할 수 있을 정도는 아닐 것이다. 아마 이 과정이 CPU의 활용률을 높이는 원인이지 않을까 생각한다.
Join의 경우 두 종류의 서버에서 상당한 퍼포먼스 향상이 있었다. 분산서버의 경우 수평 확장이 있었던 만큼 2배에 가까운 퍼포먼스 향상을 볼 수 있었다. 하지만 그럼에도 향상이 100%에 못 미치는 이유는 API 요청이 모든 Pod가 공용으로 사용하는 Ctrl Plane과 로드밸런서를 거치기 때문에 Pod의 증가가 온전히 퍼포먼스 증가로 연결되지 못했기 때문으로 보인다. 단일 서버의 경우 60.6%의 성능 향상이 있었다. 여기서 눈여겨볼 점은 바로 status이다. status의 CPU 사용률을 보면 163.5%라고 나타난다. CPU와 memory가 모두 여유가 있음에도 활용하지 못하는 이유는 DB 서버의 Join 연산 처리 한계로 병목현상이 발생했기 때문일 것이다.
마지막으로 Write 요청의 경우 Kubernetes Cluster의 퍼포먼스가 Single Server의 퍼포먼스보다 절반을 조금 넘는 것을 확인 할 수 있다. 자원 활용도를 본다면 Test A, B 모두에서 두 서버 모두 한계치에 가까운 CPU 자원을 활용하고 있지만 CPU 자원이 2배가 되었다고 퍼포먼스가 향상되지 않았고 오히려 약간 하락했다. 원인을 한참 고민해 보았다. Test에 사용한 Write API는 유저의 내 운동 목록에 운동을 하나 추가하는 API이다. 이를 처리하기 위해 서버 내부에선 굉장히 많은 동작이 이루어진다. 요청을 받은 서버는 먼저 요청에 포함된 JWT 토큰을 해독하여 User ID를 찾고 DB조회를 통해 User 정보를 읽어온다. User 정보는 유저의 운동목록 정보를 포함하고 있고, 여기서 첫 번째 운동 목록을 찾은 다음 비로소 해당 목록에 API로 전송한 운동을 추가하는 Write 하는 작업이 이루어진다. API는 단순히 DB를 작성하는 것 뿐만 아니라 그 과정에 조회와 Join이 상당히 많으며 이는 테스트 결과에 상당히 복합적인 영향을 미치었다.
그렇다면 이 실험 결과가 무의미한 것인가? 아니다. 우리의 실험 목적은 단순히 분산서버와 단일서버의 성능 비교가 아니라 우리가 새로 개발한 Kubernetes Cluster 서버와 기존 서버와의 성능 비교가 목적이다. 지금 얻을 테스트 결과를 통해 우리는 새로 개발한 서버의 DB Write 퍼포먼스가 기존 서버에 비해 낮다는 결론을 얻었고, 과정에서 알게 된 원인으로 지목되는 복잡한 인과관계들을 분석하여 향후 성능 개선을 하면 된다.
추가 테스트
추가 Test 계획
처음 계획했던 2번의 Kubernetes Cluster의 Read 테스트에서 Pod에 CPU 자원을 충분히 할당하지 않아 병목 현상이 발생했다는 결론을 내렸었다. 이를 검증하기 위해 Pod에 할당되는 자원의 상한을 CPU 950m, memory 900 Mib로 각각 90%, 125% 증가시킨 뒤 2개의 Pod를 생성하고 오토스케일링 없이 Read의 퍼포먼스를 확인하겠다. 4개의 Pod를 생성해서도 테스트하고 싶지만, AWS 비용을 분담해야 하기 때문에 비싼 자원을 마음대로 쓰기가 어려웠다. 그래서 아쉽지만 2개 Pod로 타협을 보았다.
Test B의 Single B의 Join에서 서버의 CPU, memory 모두 충분히 활용되지 않았었다. 이를 두고 네트워크 또는 DB 서버의 처리 한계가 병목지점이라는 잠정적인 결론을 내렸다. 이를 확인하기 위해 Pod의 CPU 한도를 높게 설정한 Kubernetes클러스터에서 동일한 테스트를 진행하고 TPS가 증가의 증가 여부를 확인해 보겠다.
-
Additional Test B
Write API 실험의 결과는 새로 개발한 서버의 퍼포먼스가 기존의 것보다 낮다는 것을 말해준다. 그 원인을 좀 더 세밀하게 분석하기 위해 복잡한 Join 과정 없이 정말 단순하게 DB Write만 진행하는 test API를 구현해 Single A, Single B, Kubernetes Cluster (CPU 950m, memory 900Mib, 2Pod)를 환경에서 테스트해 보겠다.
추가 Test 결과
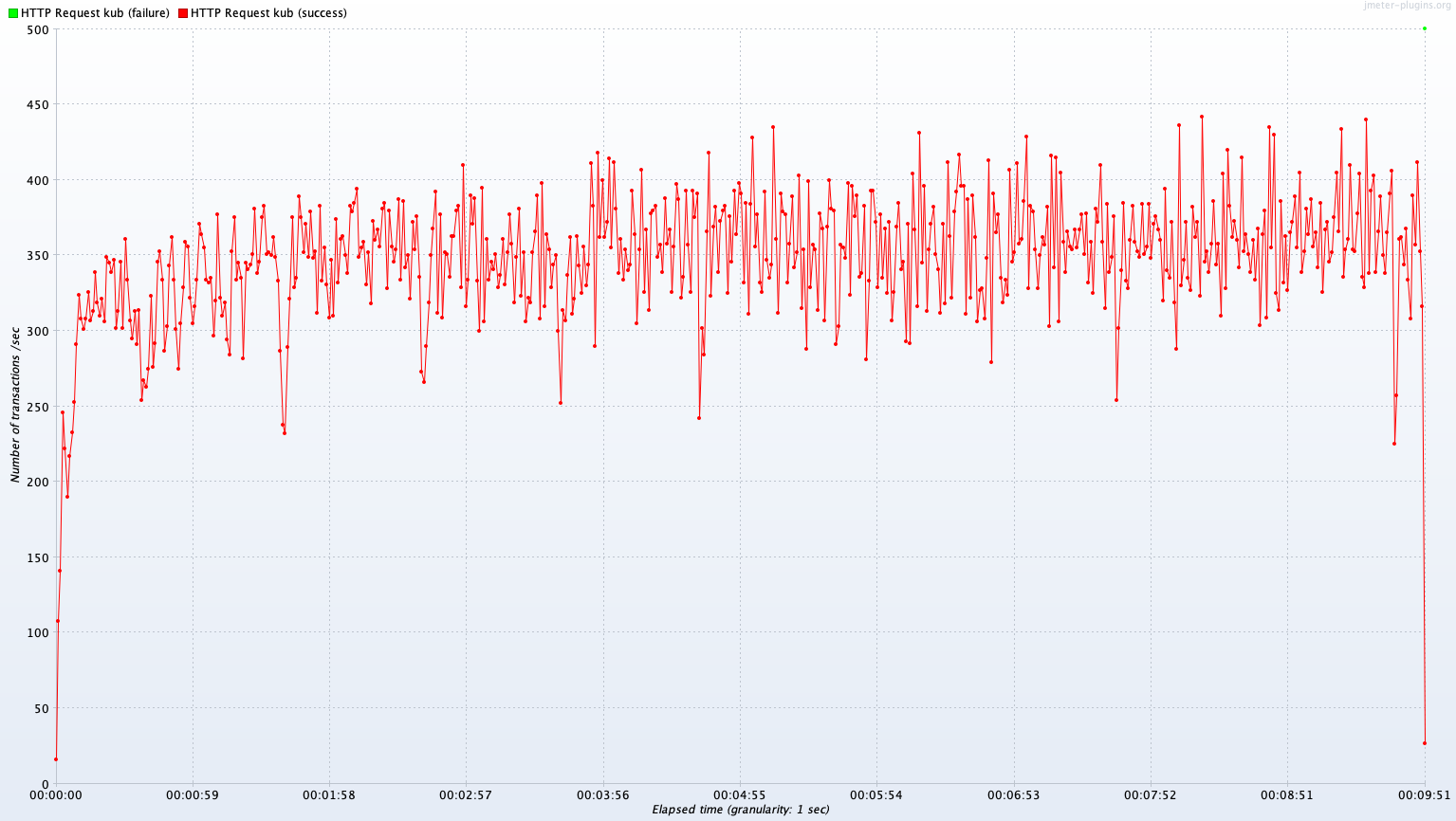
Avg TPS after 300 sec: 358.3 TPS
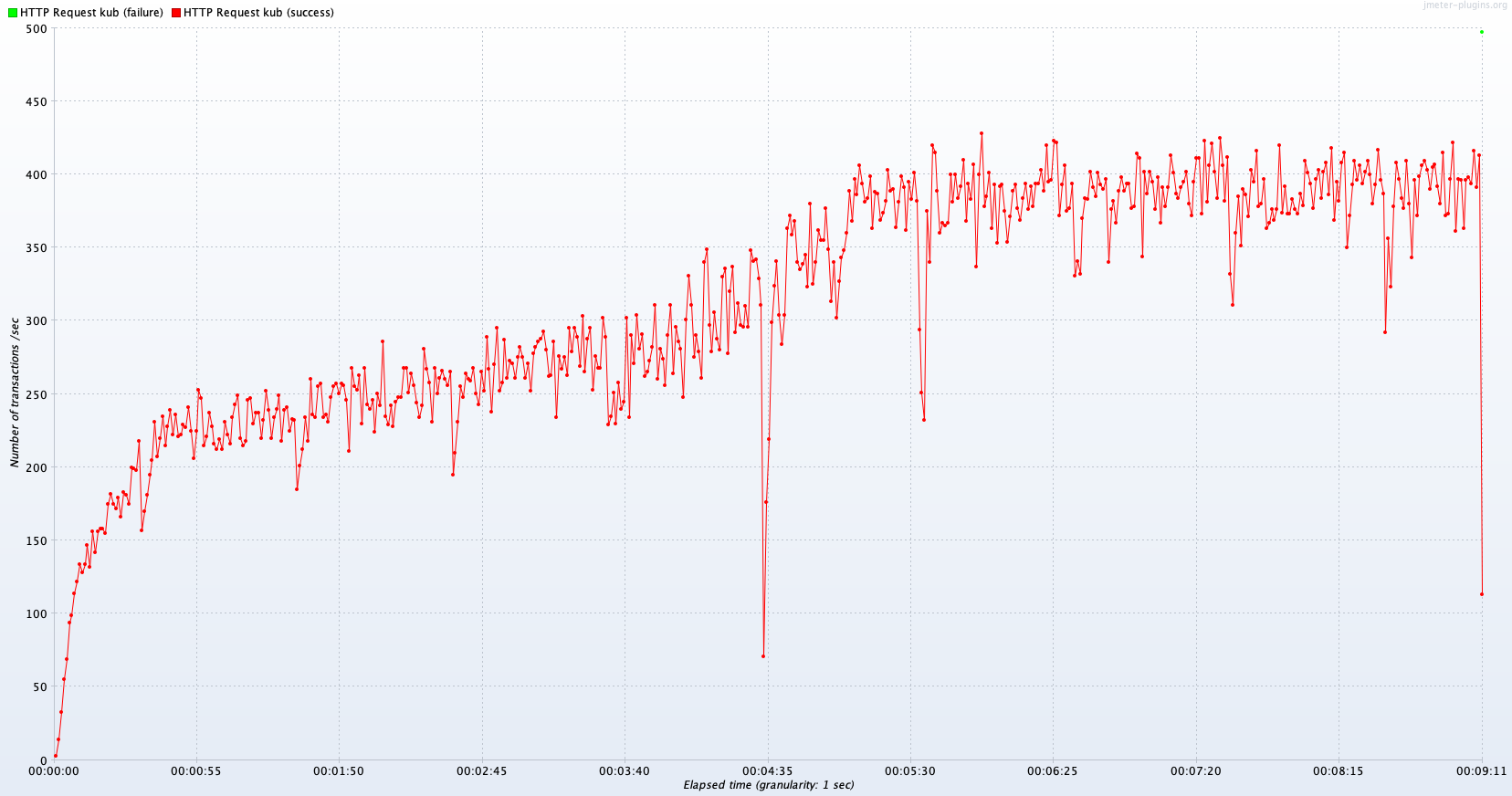
Avg TPS after 300 sec: 358.3 TPS
추가 Test 결과 분석
| Read | Join | |
|---|---|---|
| Single A | 313.9 TPS | 200.8 TPS |
| Single B | 385.1 TPS | 322.4 TPS |
| Kube (CPU 500m, Mem 400Mib, 2 Pods) | 191.8 TPS | 183.2 TPS |
| Kube (CPU 500m, Mem 400Mib, 2~4 Pods) | 343.0 TPS | 334.3 TPS |
| Kube (CPU 900m, Mem 940Mib, 2 Pods) | 358.3 TPS | 384.4 TPS |
Read에서 Kube 2~4 Pod에 비해 4.5% 성능 향상이 있었다. 자원 총량이 같은 Single B보다 여전히 성능이 뒤처진다. WAS의 기본적인 구동에 필요한 CPU 오버헤드를 낮춘 것에 대해 4.5% 성능 향상은 기대에는 못 미치는 수치지만, 향상은 확실해 보인다.
Join에서는 Kube 2~4 Pod에 비해 15.0% 성능 향상이 있었다. DB의 처리 한계가 병목지점이 맞았다면 Kube 2~4 Pod 또는 Single B와 비슷한 퍼포먼스를 보였어야 한다. DB 서버의 처리 한계가 아닌 것일까? 명확한 결론은 알 수 없었다.
정리
Kubernetes 상에 CPU 500m의 자원 제한으로 WAS의 숫자를 늘리는 것 보다 900m의 제한으로 좀 더 충분하게 CPU 자원을 주어 환경을 구축하는 것이 좋다는 결론을 얻었다. 또한 약 1,700m의 CPU 제한을 넘어서면 WAS가 병목이 아니게 된다는 것을 알 수 있었다.
처음 성능 테스트를 계획했을 때 이렇게 복잡해질 줄은 몰랐다. 그냥 모놀리식 단일 서버보다 MSA 분산 서버가 좋을 것이라는 잘못된 생각을 가지고 테스트를 설계했고, 결과로 나오는 모든 표지들이 한 방향을 가리킬 것으로 생각했다. 하지만 결론은 뒤죽박죽이었고 원인은 사방에 흩어져 있었다. 확실한 사전 준비 부족이었다. 아쉬웠던 점을 나열해 보자면
1.많은 양의 데이터를 획득했지만, 경험과 지식이 없어 이를 어떻게 조합하여 유의미한 결론에 접근하기 어려웠다.
- 초반 설계를 잘못하여 잘못된 테스트를 하며 허비된 시간이 너무 많았다. 시간은 시간대로 낭비되고, 정성껏 모은 데이터를 휴지통에 넣을 때 상당히 속이 쓰리었다.
- 더 좋은 인스턴스를 대여하여 테스트를 하고 싶었지만, RDB Burst Token 소진, 트래픽에 대한 요금 등 예상하지 못했던 변수들이 있어 시도하지 못했던 것도 큰 아쉬움으로 남는다.
이번 부하 테스트는 성공보다는 성장통에 가까운 것 같다. 보고서에 기록하진 않았지만, 결론에 닿지 못한 수많은 테스트들이 있었고, 그 속엔 불완전하지만 유의미한 배움이 있었다. 당장은 취업에 집중해야 하지만, 취업 시즌이 끝나고 서버 아키텍처에 대해 좀 더 공부한 뒤 경험을 살려 좀 더 나은 부하 테스트를 해봐야겠다.

There are currently no comments on this article
Please be the first to add one below :)
내용에 대한 의견, 블로그 UI 개선, 잡담까지 모든 종류의 댓글 환영합니다!!