들어가며
2022.01.06.
인간의 인지에 대한 몇 가지 가설
우리는 시각, 청각, 촉각, 후각, 미각으로 세상을 지각한다. 5각 외의 제6의 감각이 있다는 주장이 있으나 과학적 근거가 부족하고, 나 역시 5각이 감각의 종류가 아닌, 기관을 기준으로 인간이 분류한 것이라고 생각하지만(피부로 느껴지는 공기의 떨림과 압력 촉각이나 달팽이관이 감지한 떨림과 압박은 청각이 되는) 주제를 벗어나기 때문에 일단 5각으로 정리하고 넘어가겠다. 5각은 우리가 세상을 인식하는 도구로 감각 기관으로부터 들어온 정보는 뇌로 전달된다. 이 과정을 지각 이라고 하겠다. 지각의 행위는 단발성으로 끝나지 않고 연속적으로 이루어져 찰나의 순간에 대한 지각들이 끊임없이 들어온다.
인식 과정 예시
이러한 연속적인 감각 정보들과 우리의 지식, 지식의 범위 바깥에 있지만, 감각 정보 처리에 (의식, 통제하기 어려운) 섞이는 여러 요인들(Ex. 당시 기분, 선천적이고 동물적인 본능, 후천적으로 형성된 습관 등..)에 의해 지각한 대상들에 대한 각각의 표상이 만들어진다. 지금 내 인식 과정을 예로 잠시 상상의 시간을 갖겠다. (나는 지금 집 앞 스타벅스 2층에서 레몬 계피차를 옆에 두고 노트북으로 문서작업 중이다.)
지각(찰나)
시각: 초점의 중심에 하얀색, 검은색, 주변부로 갈수록 색깔 간의 경계가 흐려지는 어두운 주황색과 흰색, 검은색, 하늘색
청각: 찰나의 진동(연속적이지 않기에 소음인지 음악인지 구분되지 않는다.)
촉각: 불쾌하지 않을 온도, 무겁지 않은 공기, 턱, 입과 코를 지긋이 누르는 무언가, 족부에 느껴지는 압박, 아킬레스건을 찌르는 무언가, 손가락에 느껴지는 무언가, 둔부 뼈와 가죽에 느껴지는 압력, 척추에 느껴지는 압력..
미각: 혀에서 느껴지는 쌀싸름한 감각.
후각: 아무것도 느끼지 못하겠다. (후각 신경은 쉽게 피로해진다)
여기서 지각을 표현하는 것은 이후에 일어난 일련의 지식과 여러 오요인들의 간섭을 받아 화학적인 변화가 진행된 표상에서 투입물인 지각을 추출하려는 시도이며, 시도의 결과물의 추상적인 모습을 다시 언어라는 도구로 그려내는 행위이기 때문에 실제 지각과 어마어마한 차이가 있다는 것에 주의하자. 우리가 확인할 수 있는 가장 저수준의 결과물은 지각과 지식, 그 외의 요인들이 멋대로 조합된 표상들이며 그 밑을 들여다보는 것은 표상에 분리에 필요한 지식과 의식적으로 통제하지 못한 그 외의 요인들을 섞는 추론이라는 행위를 통해서만이 가능하다 라고 생각한다.
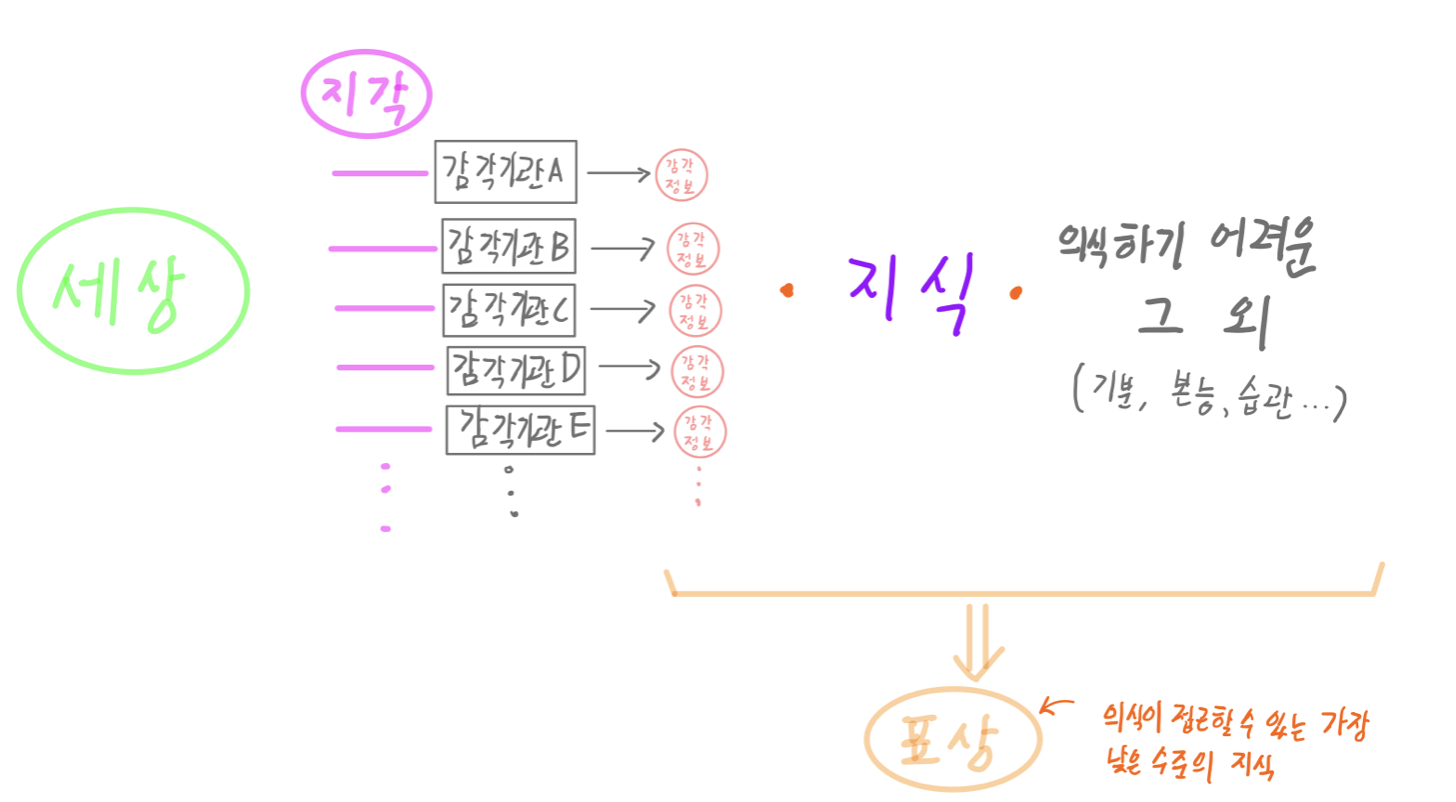 상술된 감각 정보들은 지식과 그 외 요인들이 섞여서 저수준의 표상이 만들어진다. (여기서 저수준이라 함은, 인식 과정에서 생산될 수 있는 정보 중 초기 단계의 정보들을 뜻한다.)
상술된 감각 정보들은 지식과 그 외 요인들이 섞여서 저수준의 표상이 만들어진다. (여기서 저수준이라 함은, 인식 과정에서 생산될 수 있는 정보 중 초기 단계의 정보들을 뜻한다.)
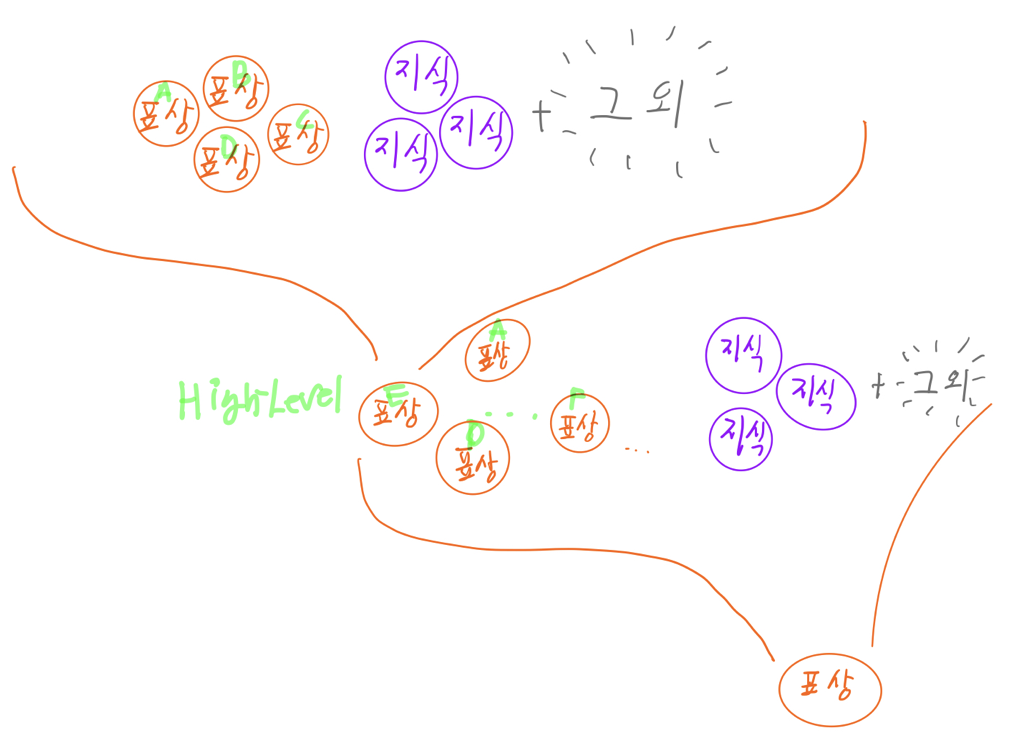 저수준의 표상은 다른 표상들, 지식 그리고 그 외 요인과 뒤섞여 점차 고수준의 표상이 되고, 이렇게 고수준으로 향하는 과정에서 우리의 정보 처리 단계에서 중요하게 고려되지 않는 표상들은 누락되어 인식의 저편으로 사라지고, 중요하게 고려되는 요소들은 중복으로 참조되어 여러 고수준의 표상들에 영향을 주게 된다.
저수준의 표상은 다른 표상들, 지식 그리고 그 외 요인과 뒤섞여 점차 고수준의 표상이 되고, 이렇게 고수준으로 향하는 과정에서 우리의 정보 처리 단계에서 중요하게 고려되지 않는 표상들은 누락되어 인식의 저편으로 사라지고, 중요하게 고려되는 요소들은 중복으로 참조되어 여러 고수준의 표상들에 영향을 주게 된다.
잠깐 아이디어 - 자연어 처리에 적용
자연어 처리 분야에서 이 개념을 사용하고 있을진 모르겠지만, 상당히 괜찮은 아키텍처를 만들 수 있을 것 같다. 언제 잠깐 위키피디아를 봤었는데 “나는 새를 보았다.”라는 텍스트를 인식한 상황을 예시로 데이터 흐름을 개략적으로 나타내 보겠다. (어디까지나 아이디어다 실제는 안 배워서 모른다)
0.정보 인식
감각 정보: {‘나’, ‘는’, ‘ ‘, ‘새’, ‘를’, ‘ ‘, ‘보’, ‘았’, ‘다’, ‘.’}
1.최초 처리
감각 정보를 저수준 표상으로 합성
-> {“나는”, “새를”, “보았다”}
2.초기 처리
초기 처리1
표상: “나는”
지식: “나(명사)” -> 我
그 외: C1 산출에 영향을 줄 수 있는 지식에 종속된 연산 장치들
결과표상 = { “나는”, “我”, C1(초진 적합도)}
C1은 상수. 지식의 사용확률(단어 사용 빈도)
텍스트 추출 위치가 법전이면 我 로써의 “나”의 출현확률은 현저히 낮아질 것이다.
일기장이면 상당히 높아진다.
법전과 같은 극단적인 상황을 제외하곤 특정 수치를 중심으로 모이는 정규화된 수치
초기 처리2
표상: “나는”
지식: “날다(飛)” + ㄹ탈락 + “는”
그 외: …
결과표상 = { “나는”, “飛” , C2}
초기 처리3
표상: “나는”
지식: “나다(풍기다)” + “는”
그 외: …
결과표상 = {“나는”, “풍기다”, C3}
{나는 / 새를 / 보았다}로 구분한 일차적인 결과표상들이 모두 산출된다.
3.결과표상 재처리
Ex. {“나는”, “풍기다”, C3} 의 적절성 판단
다른 결과 표상들 중 대상이 될 수 있는 목적어 등이 있는지 등을 고려해 각 후보의 C들을 이용해 상수 K를 연산
-> {“나는”, “풍기다”, C3, K3} 표상 생산.
{\$1, \$2, \$3, \$4}
이라고 할 때 \$1이 같은 표상들을 \$4 기준으로 내림차순 정렬,
{“나는”,“我”, \$3, \$4}, {“나는”, “飛”, \$3, \$4} , {“나는”, “풍기다”, \$3, \$4} …
4.최종표상 산출
정렬된 재처리 결과물들을 앞에서부터 비교해가며
-> 최종적인 \$2 들의 조합들을 몇 가지 결정. (1~3개)
{\$2, \$2, \$2, Z} (Z는 \$4를 이용해 연산한 조합의 적절성 수치)
(\$2 조합은 추상적인 결과물, 이걸 이용해 번역하는 것은 또 다른 처리가 필요)
정리
위 모습은 인간의 인식에 가깝기보단 프로그래밍적 타협이 들어가 결과표상들이 기존의 지식과 독립적인 어떤 추상적인 형태를 띠는 것이 아니라 지식에 대한 적절성(C, K, Z)으로 표현되었는데 조금만 더 인간의 인식에 가깝게 몇 가지 추가할만한 상상들을 더해보겠다.
-
최종표상 산출의 결과 조합 중 대부분의 \$2가 같거나 유사하고, Z의 수치가 상당할 경우 중의적 표현으로 처리하는 기술
- 초기 처리에서 그 외의 비중을 높히는 방안
2.1. 지식의 감정 벡터를 보관, 맥락상 감정 벡터와 유사도를 C에 반영
2.2. 전후 텍스트에서 유사한 지식의 사용 빈도를 산출하여 C연산에 사용 그 외 다수 - 지금보다 더 추상적인 지식 \$2의 데이터베이스 구축.
- 초기 처리에서 하나의 \$2가 아닌 다수의 \$2를 사용하여 고차원 벡터화

There are currently no comments on this article
Please be the first to add one below :)
내용에 대한 의견, 블로그 UI 개선, 잡담까지 모든 종류의 댓글 환영합니다!!