도입
프로그램과 프로세스
프로그램과 프로세스에 대한 아주 짧은 개념 정리를 하고 본 내용으로 넘어가자
-
프로그램
디스크에 저장된 instruction과 Data로 이루어진 정적인 코드 덩어리
-
프로세스
실행중인 프로그램 (프로그램의 인스턴스)
여러가지 하드웨어가 프로세스의 실행을 도와준다.
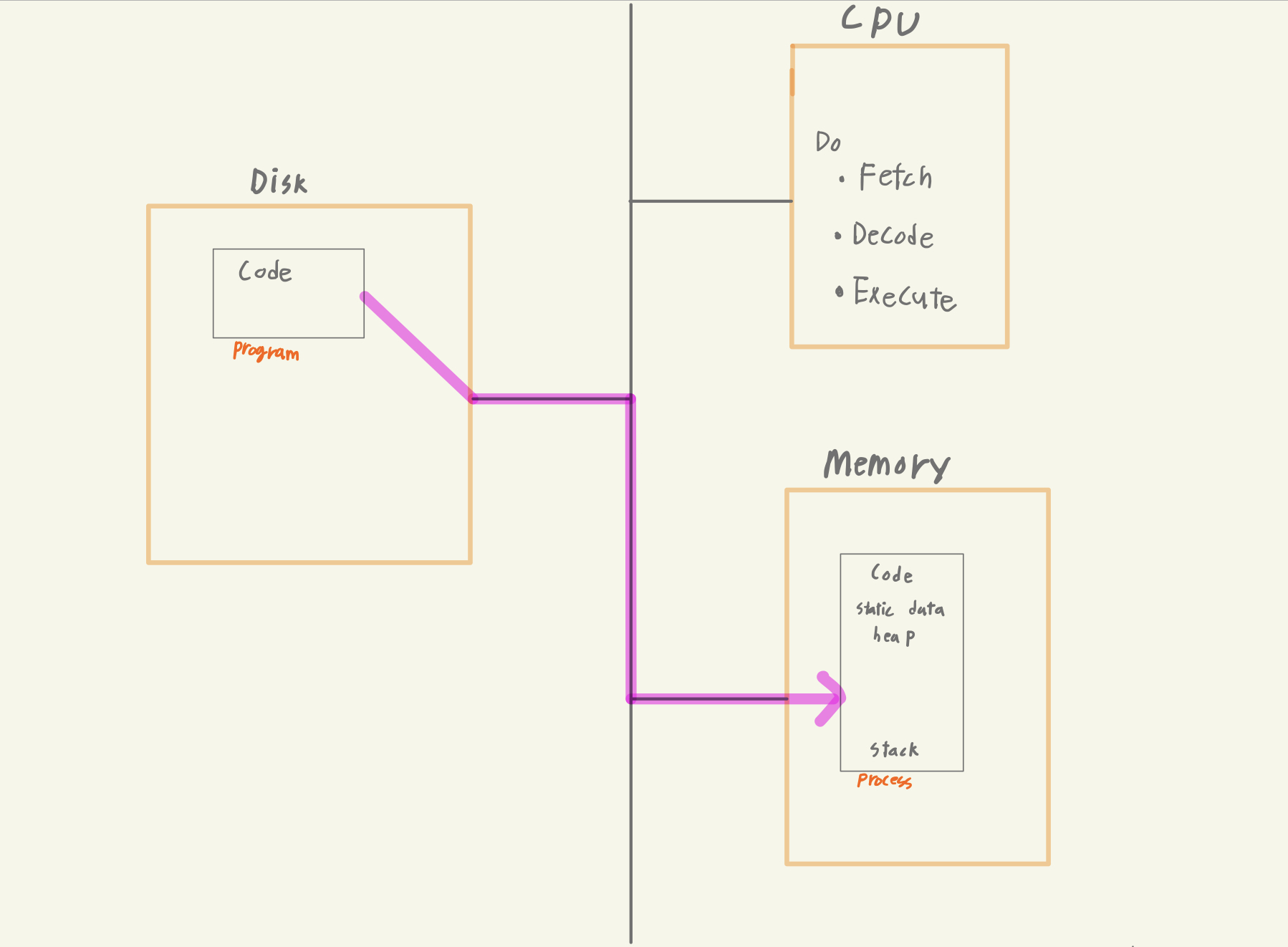
-
메모리
프로세스가 실행할 명령과 데이터를 보관
그 외 다수 -
CPU 레지스터
프로그램의 카운터- CPU가 실행할 instruction의 메모리 주소를 가리키는 것
stack pointer - 스택의 탑이 어딘가?
그 외 다수 -
그 외 다수
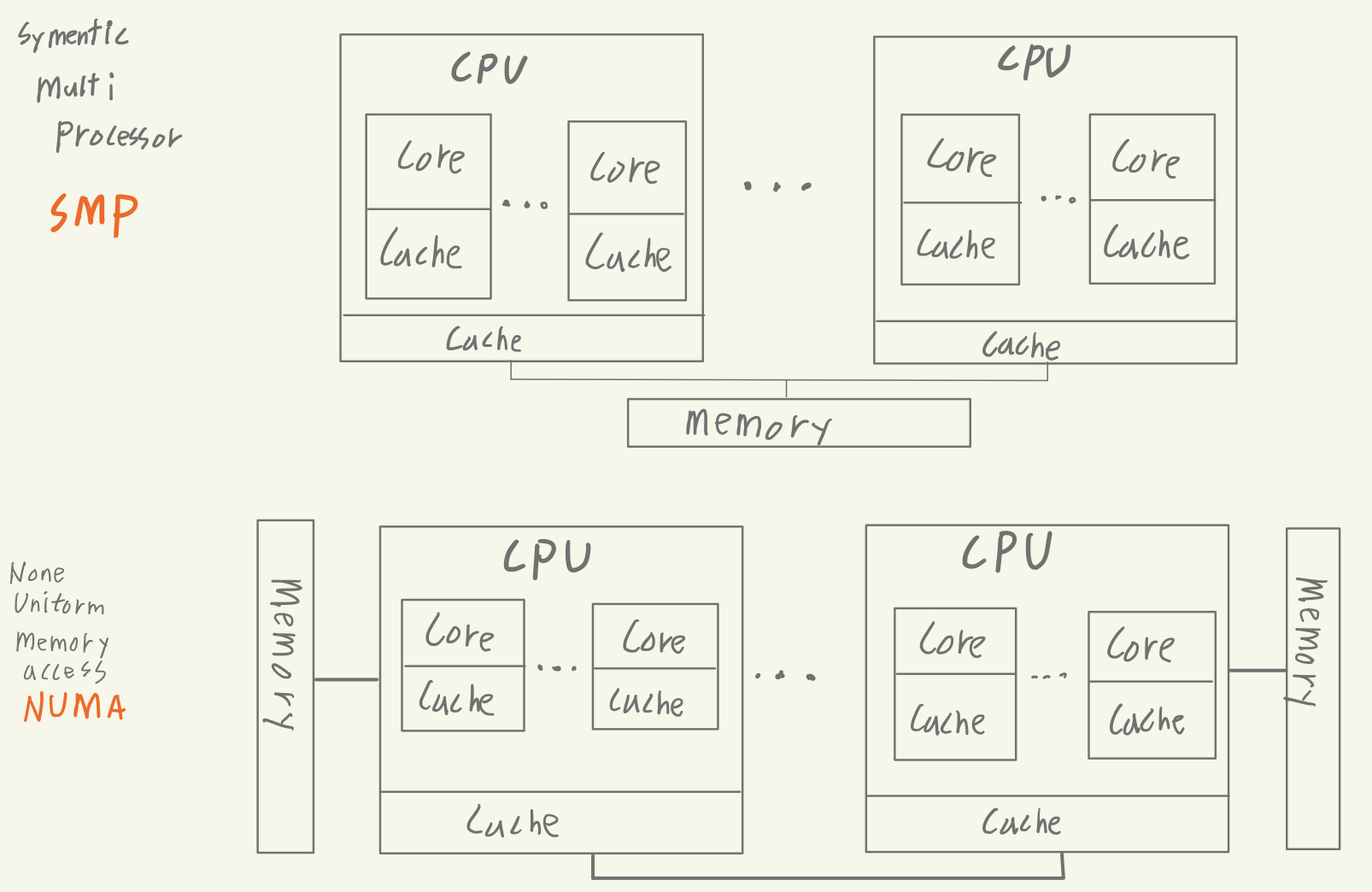
우리의 컴퓨터는 수많은 프로세스를 동시에 실행시킨다. 크롬도 실행해야 하고 음악도 재생해야 하고, vsCode도 돌려야 하고…
하나의 프로세스를 실행하는데엔 하나의 CPU가 필요한데 CPU(Core)는 알다시피 우리의 컴퓨터에 몇 개 없다.
cpu와 core (네이버 백과)
수십 개의 프로세스를 동시에 실행시킬 수 있는 비결은 운영체제가 자원들에 대한 가상화(Virtualization)를 해주기 때문이다.
2가지 자원에 대한 가상화가 필요하다.
- CPU
- Memory
Part_1 에서는 CPU 가상화에 대한 내용을 다룰 것이다.
CPU Virtualization
CPU 가상화는 CPU의 Time Sharing을 통해 실현된다. CPU는 분명 하나지만, 여러개의 프로세스를 매우 짧은 간격으로 조금씩 실행시킨다면? 사용자는 여러 개의 프로세스가 동시에 실행되는 것 처럼 느낄 것이다.
그런데 이렇게 하면 모든 프로세스가 감질나게 조금씩만 실행되며 결국 여러개의 프로세스를 하나씩 시작부터 종료까지 순차적으로 실행하는 것과 같은게 아닐까?라는 의혹이 들 수 있으나 결론부터 말하자면 몇몇 특수한 프로세스를 제외하곤 그렇지 않다. (그런 특수한 프로세스를 위한 운영체제는 따로 마련되어있다. ex. 하루종일 CPU만 사용하며 연산만 하는 기계라던가…)
Three State of Process
여러 개의 프로세스의 CPU자원 점유 시간을 적절하게 조정하여 이들이 동시에 실행되는 듯 하게 하는 것을 Time Sharing 이라고 하며 운영체제가 이 Time Sharing 기능 집행하는 것을 Scheduling 이라고 부른다.
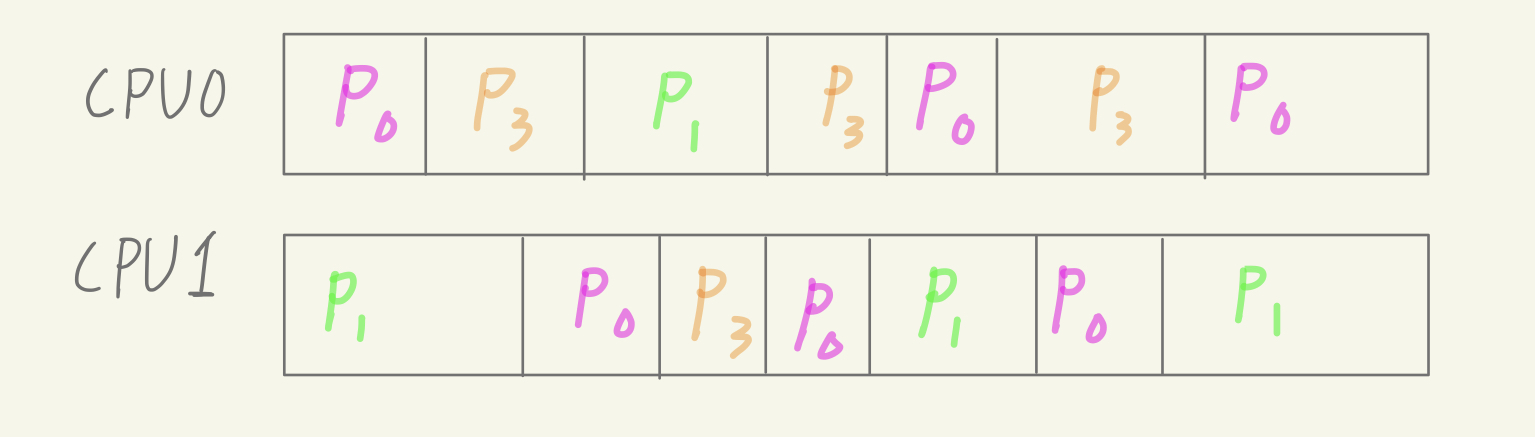
운영체제의 Scheduling으로 프로세스는 CPU자원을 받고, 반납하고, 뺏기고… 하게된다.
이런걸 보면 운영체제가 갑, 프로세스가 을 으로 느껴질 것이다. 사실… 운영체제를 개발 할 때 프로세스를 greedy하다고 가정한다.
여긴 타당한 이유가 있다. 먼저, CPU 자원이 할당된 상태에서만 프로세스가 연산을 할 수 있다. 어떤 프로세스가 CPU자원을 계속 잡고 있으면 그 프로세스의 실행에 필요한 연산들을 CPU가 즉시즉시 실행해 줄 것이며 이는 해당 프로세스의 실행 성능을 제고한다.
프로그램 개발자 입장에선 자신의 프로그램의 성능이 좋아보이기 위해 CPU 자원을 최대한 많이 할당받으려 할 것이다. 이런 프로세스를 상대해야 하는 운영체제의 개발은 일단 모든 프로세스를 greedy 하다는 가정을 하고 진행된다.
운영체제의 Scheduling에선 실행중인 프로세스의 상태(state)를 3가지로 구분한다.
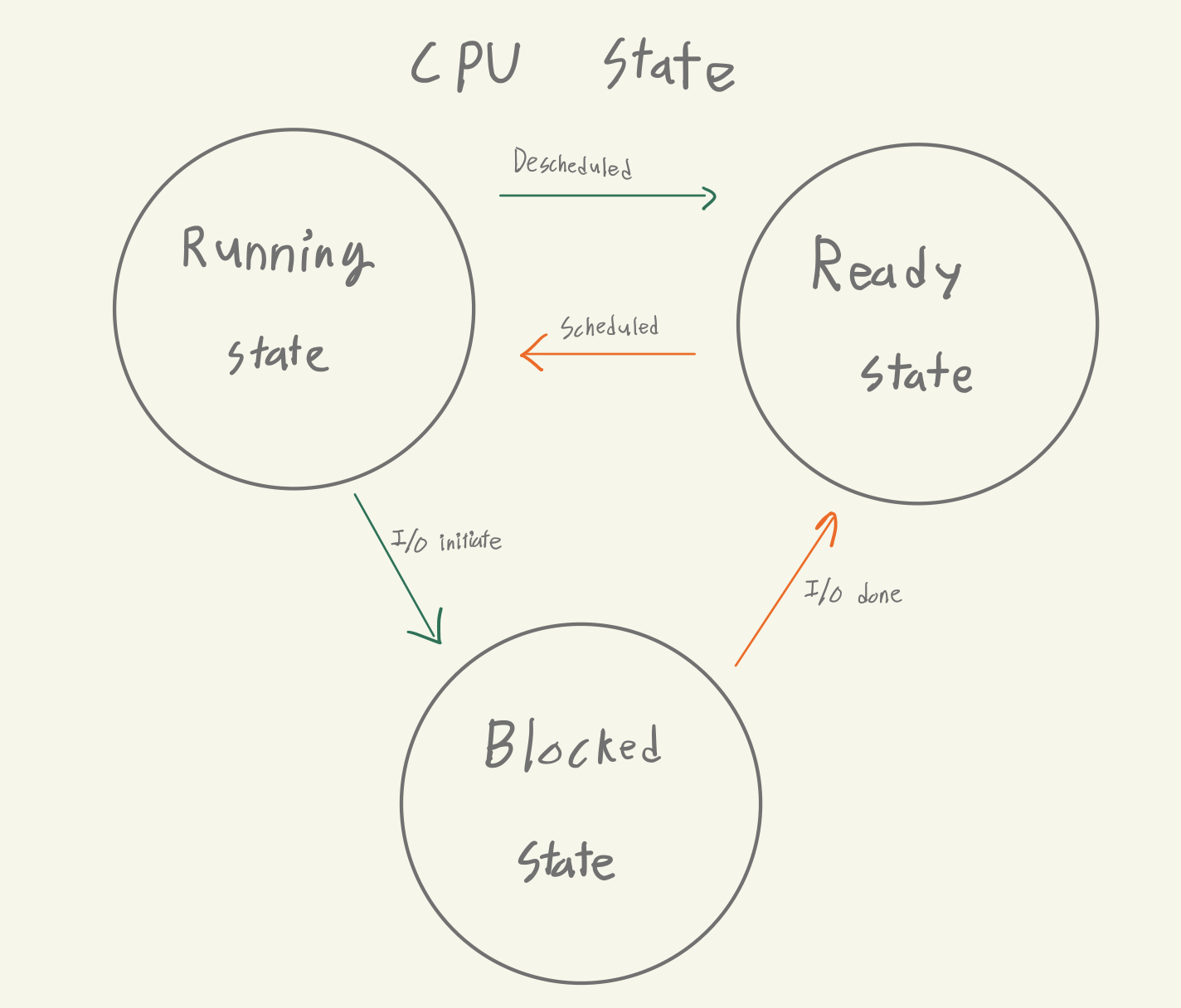
3가지 State
-
Running State
프로세스가 CPU 자원을 할당받아 실행중인 상태
-
Ready State
CPU 자원이 할당되면 언제든 실행될 수 있지만, 현재 할당 받지 못한 상태
-
Blocked State
프로세스가 I/O 요청을 하거나 wait 시스템 콜 등을 하여 CPU 자원이 할당되더라도 실행할 수 없는 상태(CPU자원도 당연히 회수된다. 효율을 위해)
일반적으로 I/O 장치들에 데이터를 요청하고 응답을 받기 까지 시간이 오래걸리고, 응답을 받기 까진 다음 명령줄로 이동할 수 없으므로 운영체제는 I/O시스템 콜이나 wait 시스템 콜이 있을 때마다 프로세스를 blocked 상태로 돌리고 CPU자원을 회수해간다.
간단한 예시
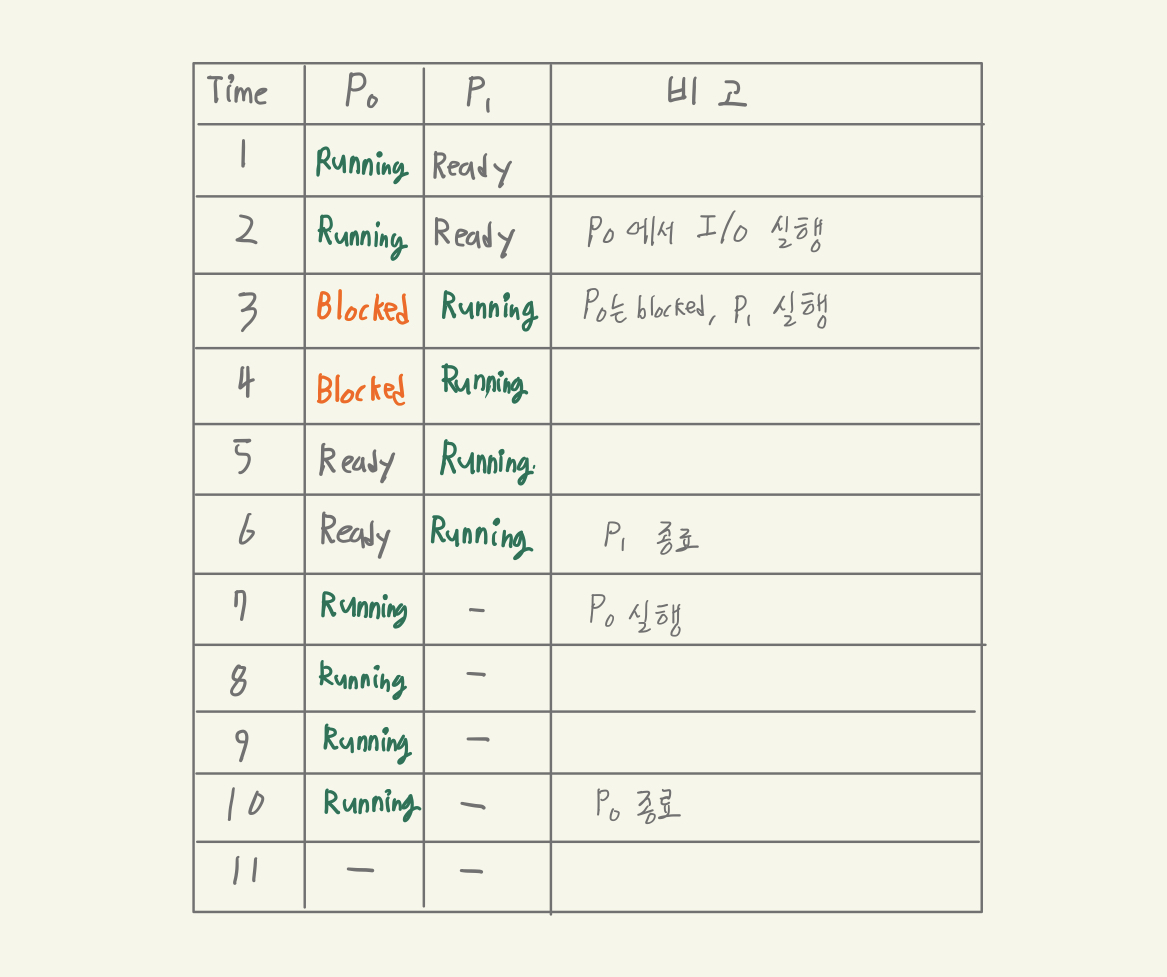
Limited Direct Execution
그런데 이 Scheduling 을 집행하는 것도 연산이 필요한데(연산엔 CPU자원 필요) 어떻게 탐욕스러운 process들을 상대로 CPU 자원을 뺏어 올 수 있을까??
I/O 작업은 다른 장치를 읽고 쓰는 작업이다. Disk를 프로세스가 마음대로 쓸 수 있다면 운영체제의 데이터가 보관된 곳 같이 시스템에 치명적인 장소의 데이터를 보호할 수 없다. I/O 작업 또한 프로세스가 사용하도록 허용된 위치에서만 실행되어야 한다. 여기에도 운영체제의 감독이 필요하다. I/O와 같이 운영체제의 감독이 필요한 작업들은 프로세스가 독자적으로 실행할 수 없도록 제한을 하고, 운영체제로 컨트롤을 이양해서 이런 필요하지만, 마음대로 하게 둘 수는 없는 작업들을 실행할 수 있게 해야 한다. Scheduling 하다가 엉뚱한 소리가 나온 것처럼 느낄 수 있지만, 둘은 연관되어 있다. 방금의 문제와 Scheduling을 위한 운영체제 간섭을 을 동시에 해결 할 수 있는 방법이 있다.
바로 프로세스의 모드를 User Mode, Kernel Mode 2가지로 분리하는 것이다.
프로세스가 그냥 CPU를 사용하는 단순 연산 작업을 하는 것은 User Mode에서 이루어진다. 그러나 I/O와 같이 운영체제의 관리가 필요한 작업은 User Mode에서 할 수 없고, Kernel Mode 로 변경해 주어야 하는데 이를 위해 운영체제는 System Call 이라는 기능을 제공한다. 즉, User Mode 에서 동작하던 프로세스가 Kernel Mode에서만 가능한 동작을 해야 할 때 해당 동작에 대응되는 System call함수를 이용한다.
I/O 외에도 fork(), exit() 과 같은 프로세스 제어, pipe()와 같은 통신, chmod(), chown()과 같은 보안 의 역할 등 kernel mode에서만 실행 가능한 동작들에 대한 System Call이 있다.
Trap Instruction
그런데 System Call 함수에 프세스가 마음대로 접근하여 하고싶은 것을 모두 이루어주는 요술 방망이로 전락하게 두어선 안된다. 이를 위한 보안 장치가 바로 Trap 이다.
정리하자면!
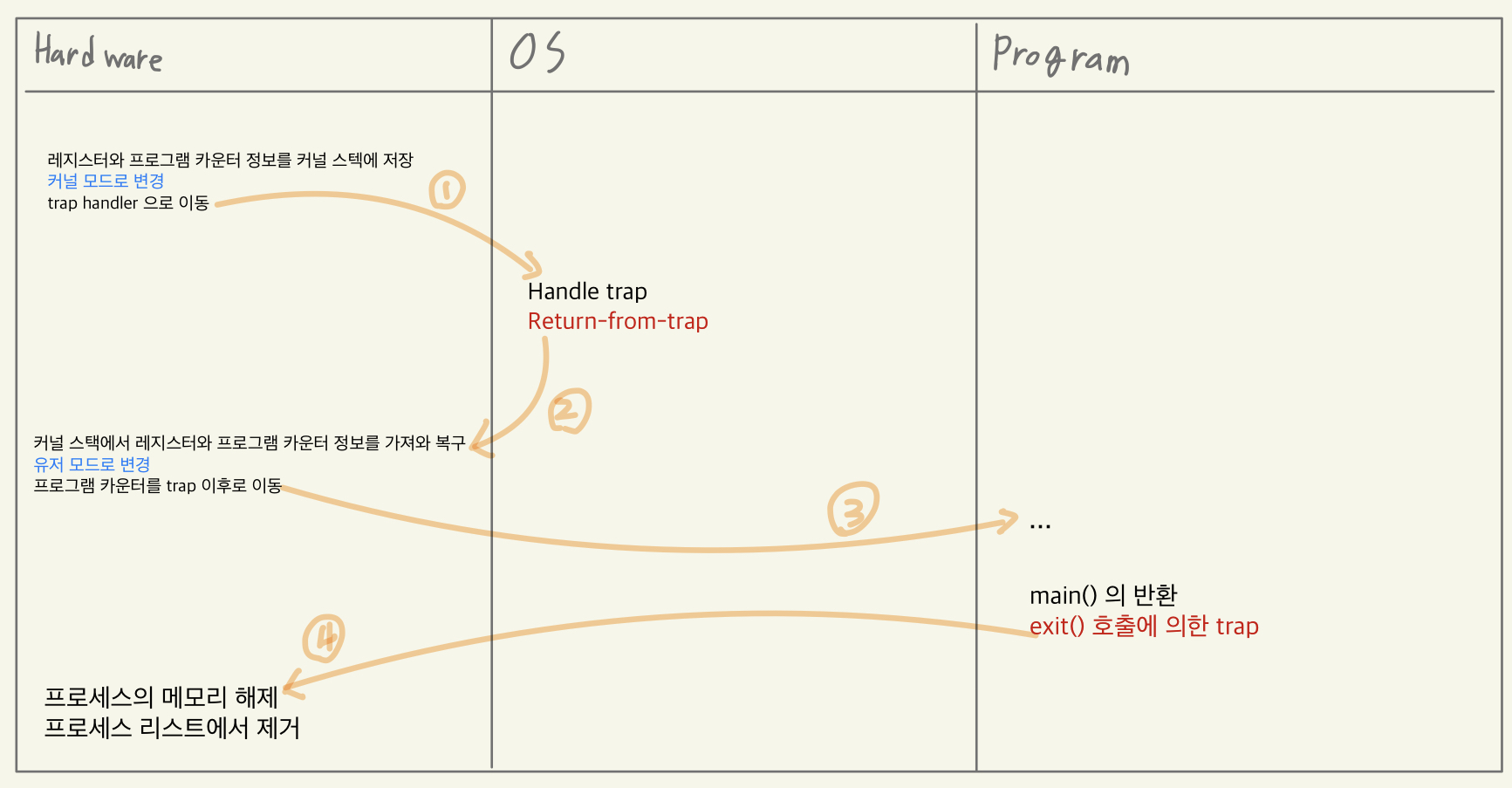
Process 가 평소의 User mode 로 실행되고 있을 때 User Mode 에선 실행할 수 없는 Restricted operation을 실행하려고 하면 trap Exception이 발생한다. 프로세스 모드가 kernel 모드로 전환되고, 호출된 trap Exception을 처리하기 위한 trap handler의 주소를 trap table에서 탐색하고 호출한다. trap handler는 Restricted Operation을 실행하는 System call function을 호출하여 실행한다. System call function이 종료되면 trap handler는 Kernel Mode에서 원래의 User Mode로 복귀하는 Return-from-Trap instruction을 수행한다.
-
trap table
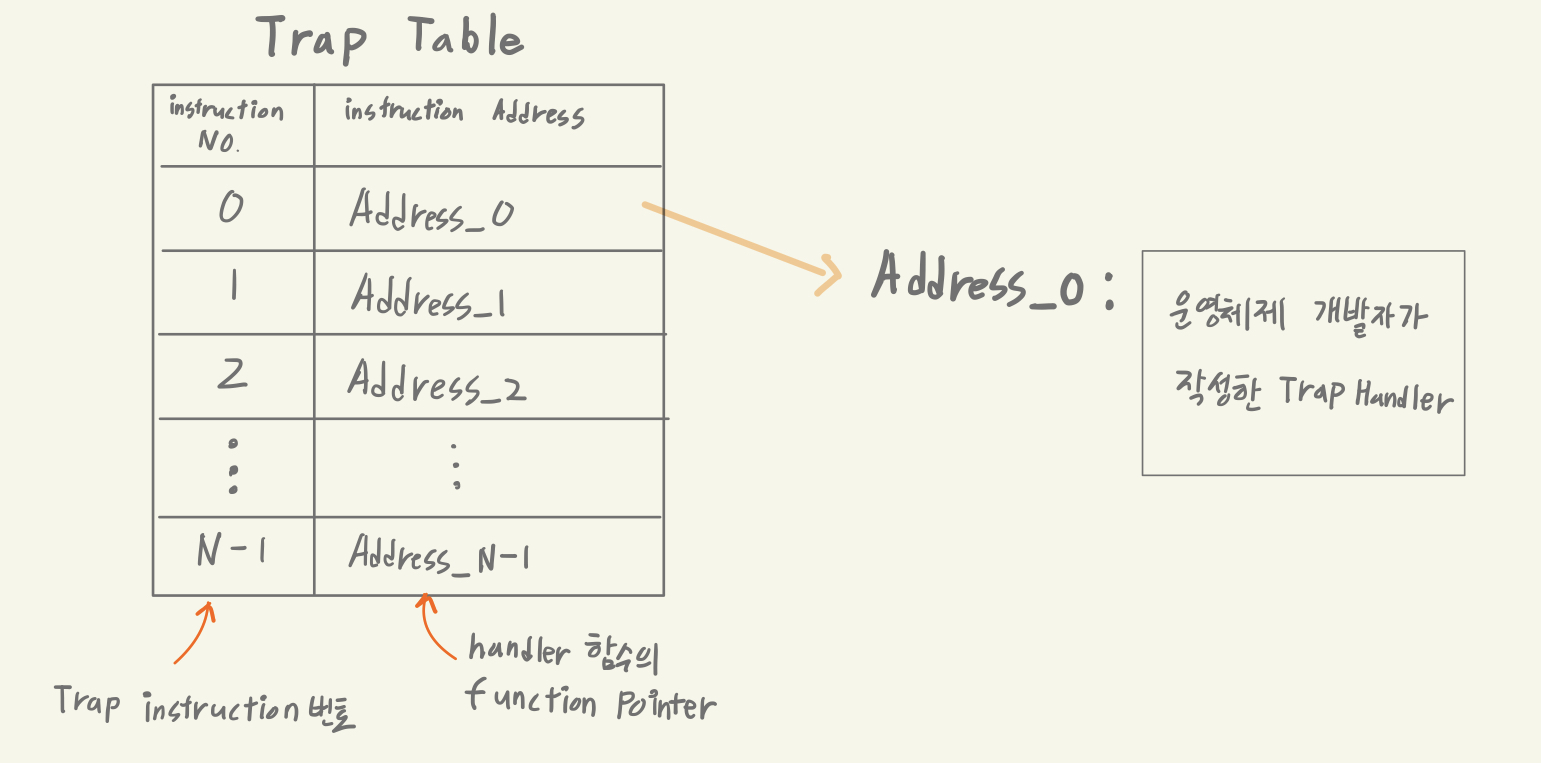
Trap Table trap table 은 trap Exeption에 대한 handler들의 주소과 보관된 테이블이다. (운영체제 개발자가 이 handler 함수를 디자인한다.) trap table은 부팅시 CPU에 저장된다.
-
Kernel Mode 로 전환
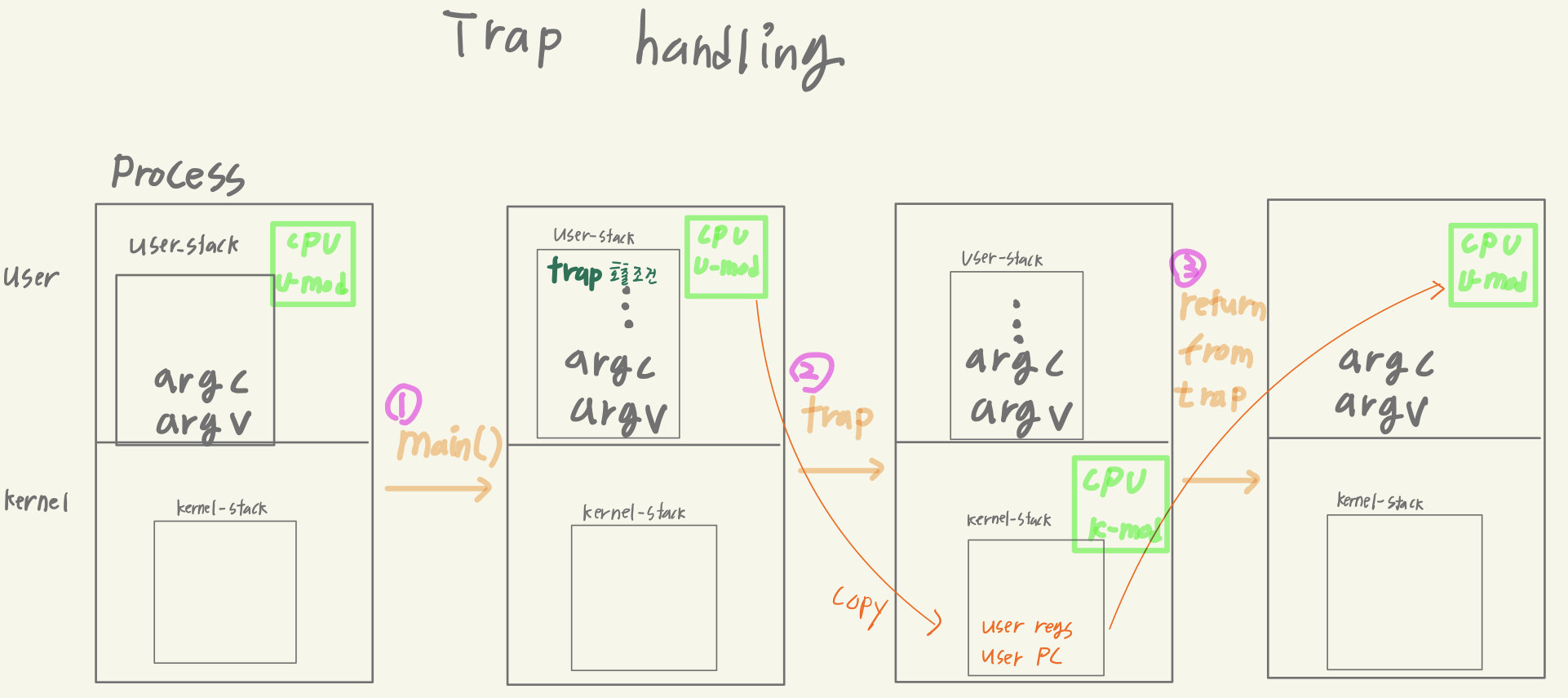
mode switch
kernel 모드로 전환된다는 것은 단순히 프로세스 모드만 띡 하고 바뀌는 것이 아니다. 실행 공간이 달라져야 한다. user stack을 떠나 kernel stack 으로 변경되고, user mode에서 실행되던 cpu의 레지스터 데이터와 프로그램 카운터 등을 복사하여 kernel stack에 보관해야 한다. 그리고 Return-from-trap 이 발동하여 user mode 로 복귀할 땐 kernel stack에 저장했던 레지스터와 프로그램 카운터 정보를 고스란히 restore 해주면 된다. -
Process Loading
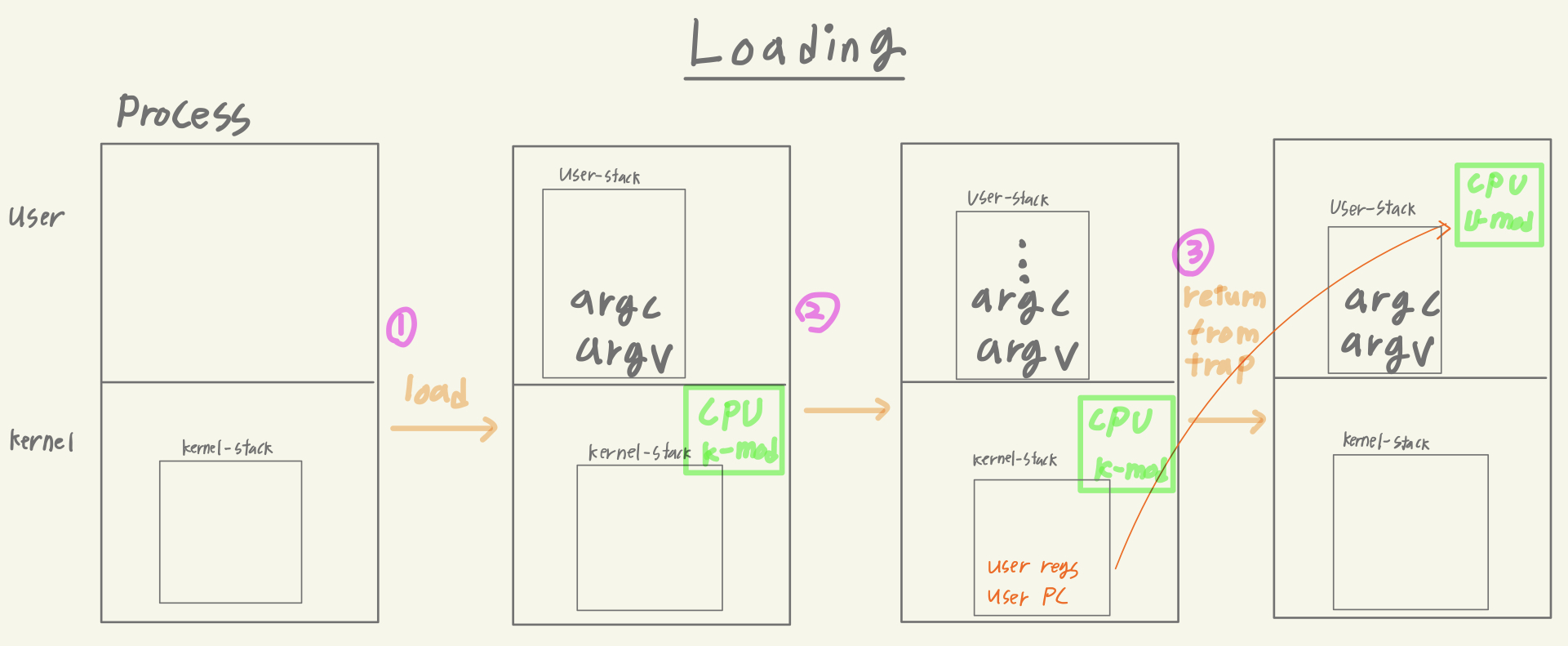
Process Loading
프로세스가 로딩되는 과정도 trap이 handle 되는 과정과 같다.
프로세스간 Switching
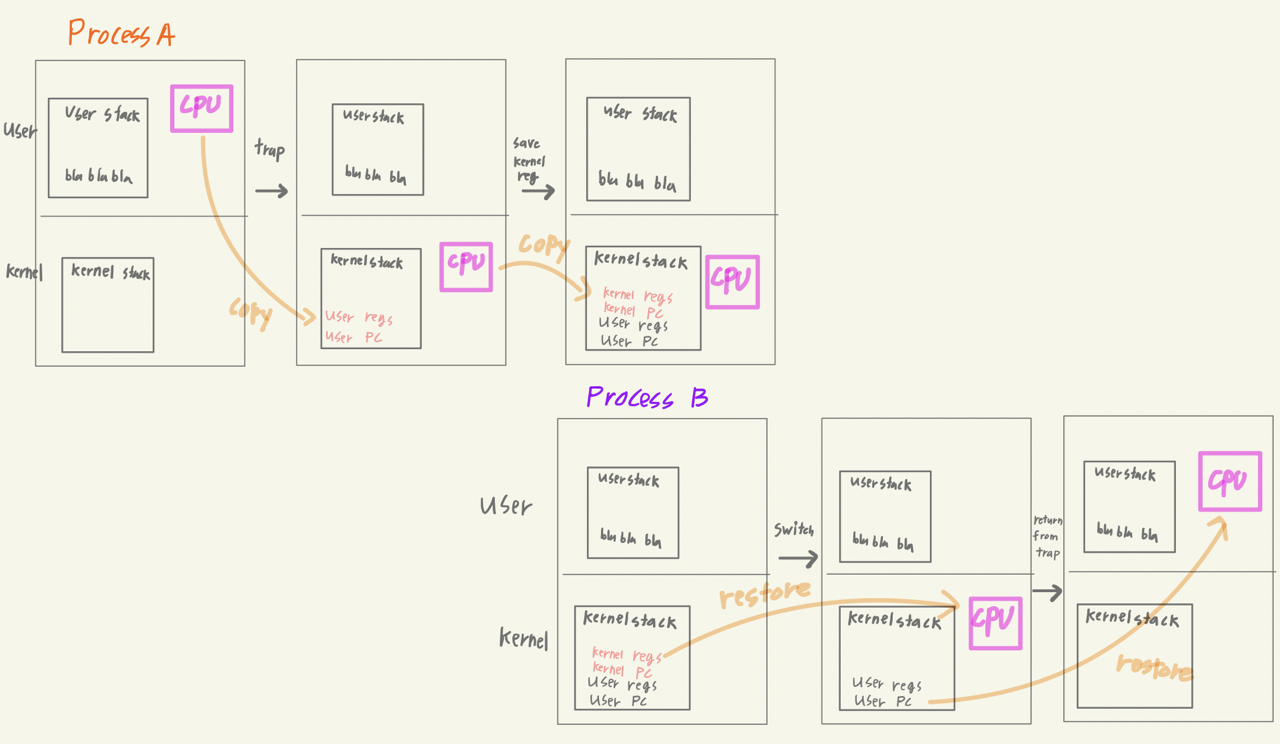
드디어 system call과 프로세스간 switchging을 연결할 수 있다. system call이 발동하면 kernel mode로 전환된다고 했다. system call 이 호출되어 I/O 요청이 하드웨어에 전송되면, 전달받기까지 꽤 걸린다. 운영체제는 CPU 낭비를 막기 위해 system call의 반환을 기다리지 않고, 프로세스를 block state로 돌린뒤 (I/O 에 대한 회신이 도착하면 Ready 로 전환된다.) Ready queue의 다음 프로세스에게 CPU를 배정한다.
위와 같이 system call 호출을 통해 kernel모드로 전환되어 자원 사용에 대한 검토를 받는 것과 같은 것은 프로세스의 자발적인 os 전환으로 볼 수 있다. 그런데 만약 system call을 전혀 사용하지 않는 프로세스라면 이런 자발적인 os 전환은 어려울 것이다. 이를 위한 장치가 하나 더 있다. 바로 Timer 인터럽트 이다.
Timer Interrupt
타이머 디바이스에서 일정 주기로 timer expire을 하도록 설정하고 그 때마다 expire 사실을 cpu에 전달하여 interrupt를 발생시키도록 하는 것이다. interrupt가 발생하면 현재 실행중인 프로세스가 정지되고, interrupt handler가 발동한다. handler에서 scheduling 정책에 따라 방금 실행중이었던 프로세스의 추후를 결정한다.
Scheduling
여러개의 프로세스가 동시에 실행되는 것 처럼 보이기 위해 프로세스에 CPU를 할당, 해제를 짧은 간격으로 반복해야 한다. 여기서 어떤 프로세스에 CPU 자원을 주고 어떤 프로세스에 자원을 회수할지의 정책을 Scheduling policy라고 하며 이를 집행하는 것을 Scheduling이라고 한다.
여러가지 Scheduling policies들 중 알맞는 정책을 선택하기 위한 2가지 기준이 있다.
-
Turnaround Time
프로세스 생성시간부터 종료시간까지의 간격을 의미한다.
$T_\mathrm{turnaround}=T_\mathrm{completion}-T_\mathrm{arrival}$
-
Response Time
프로세스가 처음 ready state 에 진입하고부터 running state 로 변경되기까지의 간격
$T_\mathrm{response}=T_\mathrm{firstrun}-T_\mathrm{arrival}$
매우 간단한 예시를 들어보겠다.
-
간단 예시1
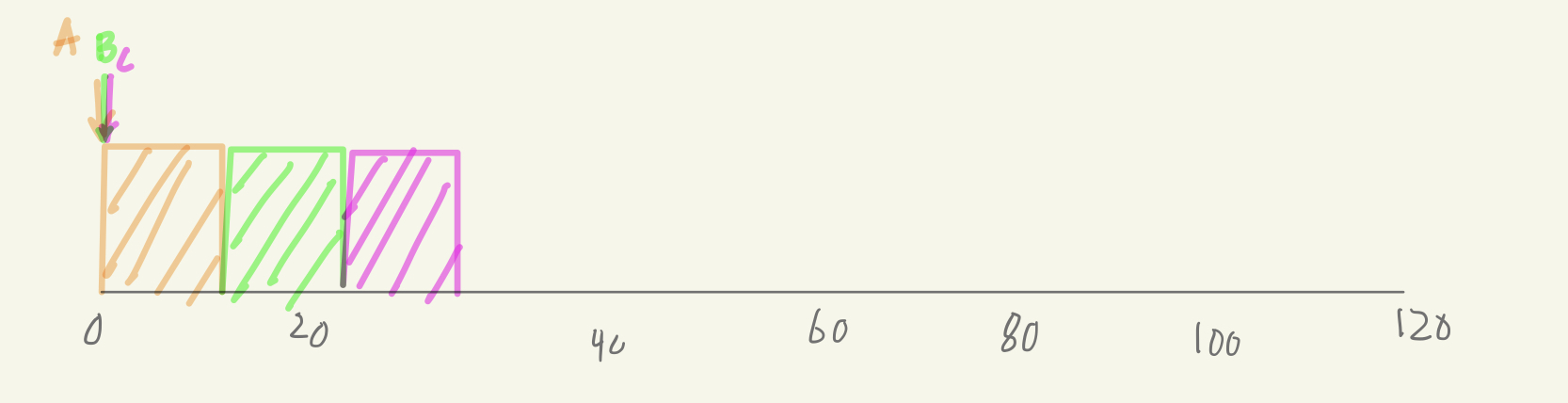
Turnaround Time의 평균 = $\frac{10+20+30}{3}=20$
Response Time의 평균 = $\frac{0+10+20}{3}=10$ -
non preemptive Scheduler
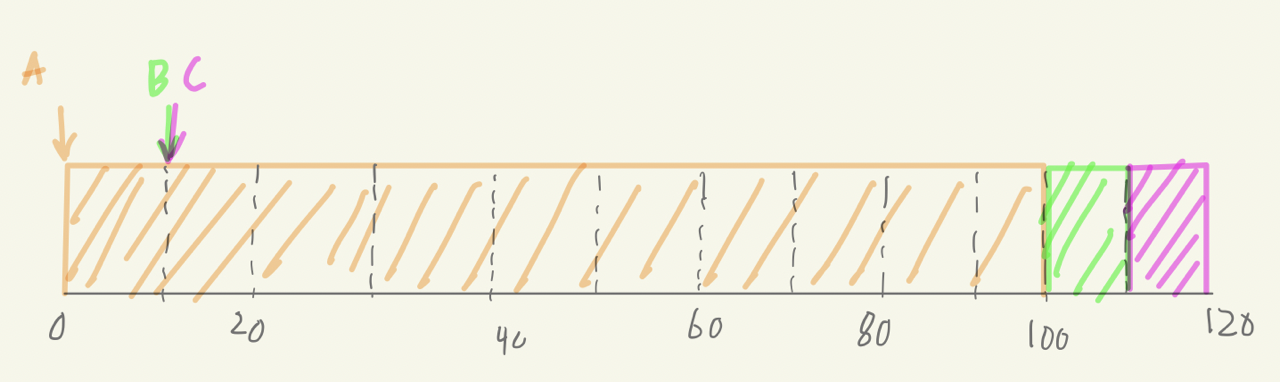
non preemptive Scheduler
Turnaround Time의 평균 = $\frac{100+100+110}{3}=103.\dot{3}$
Response Time의 평균 = $\frac{0+90+100}{3}=63.\dot{3}$현재 실행중인 프로세스가 끝날때 까지 CPU자원을 배정하는 경우 위와 같이 Turnaround 과 Response 둘 다 박살이 난다.
-
Preemptive Scheduler
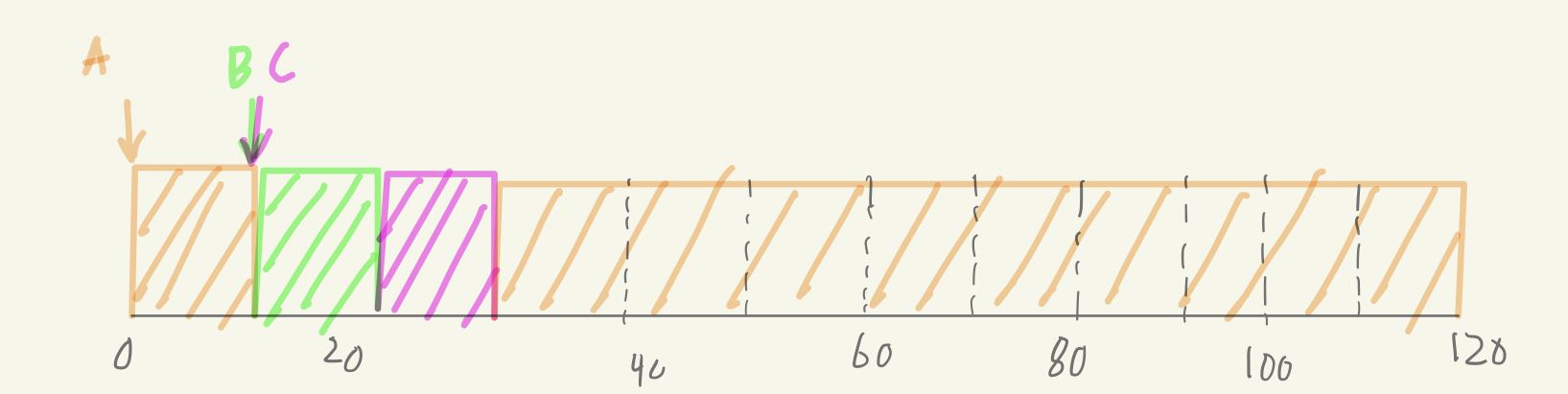
Preemptive Scheduler
Turnaround Time의 평균 = $\frac{120+10+20}{3}=50$
Response Time의 평균 = $\frac{0+0+10}{3}=3.\dot{3}$프로세스의 실행 중 주기적으러 Ready Queue를 확인하며 다른 프로세스에게도 자원을 배정하는 스케줄러이다.
-
Round-Robin (RR)

Turnaround Time의 평균 = $\frac{30+28+26}{3}=28$
Response Time의 평균 = $\frac{0+2+4}{3}=2$Preemptive 정책에서 Ready Queue 확인 주기를 아주 작은 단위로 줄인 스케줄링 방식이다.
자주 switching을 하여 오버해드가 커질 수 있으나 Response time이 극도로 짧아진다는 장점이 있다.
우리가 사용하는 일반적인 운영체제는 이 RR을 사용한다.
Multi Level Feedback Queue (MLFQ)
우리가 실행하는 프로세스들은 모두 같은 우선순위를 갖지 않는다. 사용자가 우선적으로 처리해야 할 프로세스가 있는가 하면 그냥 백그라운드에서 천천히 실행되어도 되는 프로세스가 있다.
또, 같은 우선순위를 갖고 시작한 프로세스라도 프로세스가 CPU자원을 탐욕적으로 사용하여 동 순위의 다른 프로세스에게 자원을 양보하지 않는 경향을 보이는 프로세스에 대해선 운영체제가 임의로 순위를 낮추어 탐욕을 절제시킬 필요가 있다.
어찌 되었든 이런 기능을 구현하기 위해선 여러개의 순위가 다른 Ready Queue를 운영하여야 한다.
Multi Level Feedback Queue (이하 MLFQ)는 서로다른 우선순위를 갖는 여러개의 큐를 운영하며 프로세스의 CPU 점유 경향(양보 빈도)을 보며 후속적으로 프로세스의 우선순위를 조정하는 정책을 실행한다.
각기 다른 우선순위를 갖는 큐들을 운영하는 두 가지 기본 규칙이 있다.
- 프로세스 A의 우선순위가 프로세스 B의 우선순위보다 높다면 A를 실행한다.
- A와 B의 우선순위가 같다면 둘을 RR으로 실행한다.
초기의 Priority 를 주는 것은 사용자나 운영체제의 몫이고, 후속적으로 Priority가 수정되는 기준은 무엇일까?
프로세스는 Workload를 기준으로 2가지로 구분될 수 있다.
-
I/O bound job
I/O 가 주된 Job으로 사용자의 입력을 기다리거나 파일 입출력을 빈번하게 하는 프로세스이다. 이 부류의 프로세스들은 자발적인 CPU자원 반납을 자주 한다.
-
CPU bound job
연산 등 CPU자원 소모를 주로 하는 작업이다. 이 경우 Timer Interupt이 발동하여 강제적으로 해제가 되기 전까지 계속 CPU자원을 사용하는 빈도가 높은 프로세스이다. 자발적인 CPU 반납의 빈도가 낮다.
CPU bound job이 CPU자원을 탐욕스럽게 사용할수록 I/O bound job의 실행시간은 줄어들게된다. 이는 I/O bound job이 안그래도 양보를 많이 하는데 양보를 할 기회조차 적게 주어지어 매우 낮은 CPU 점유율을 갖게 된다. 이를 막기 위해선 프로세스가 해당 우선순위 내에서 CPU 자원을 사용한 시간을 누적집계하고 time allotment라는 기준값과 비교하여 time allotment에 도달한 프로세스의 우선순위를 하향한다. 그런데 이런식으로 I/O bound job이 높은 우선순위를 독차지 한다면 CPU bound job은 점점 우선순위가 낮아져 CPU를 받지 못하는 starbation을 겪게된다. 이를 막기 위해 일정 시간마다 우선순위를 회복시키는 Boosting이라는 장치를 만든다.
Multiprocessor Scheduling
중간고사가 끝나고 시간이 되면 멀티 프로세서 스케줄링도 작성하겠다.

There are currently no comments on this article
Please be the first to add one below :)
내용에 대한 의견, 블로그 UI 개선, 잡담까지 모든 종류의 댓글 환영합니다!!